Суфіксний автомат
Суфіксний автомат — це потужна структура даних, яка дозволяє розв'язувати багато задач, пов'язаних із рядками.
Наприклад, з його допомогою можна шукати всі входження одного рядка в інший або підраховувати кількість різних підрядків заданого рядка. Обидві задачі розв'язуються за лінійний час за допомогою суфіксного автомата.
Інтуїтивно суфіксний автомат можна розуміти як стиснуту форму всіх підрядків заданого рядка. Вражає те, що суфіксний автомат містить усю цю інформацію в дуже стиснутому вигляді. Для рядка довжини він потребує лише пам'яті. Більше того, його також можна побудувати за часу (якщо вважати розмір алфавіту константою), інакше і пам'ять, і часова складність становитимуть .
Лінійність розміру суфіксного автомата вперше виявили 1983 року Blumer та інші, а 1985 року Crochemore та Blumer представили перші лінійні алгоритми його побудови.
- Багато запитів про підрядки одного тексту (входження, кількість різних підрядків, найдовший спільний підрядок) за лінійний час? (якщо задача суто лексикографічна на суфіксах → Суфіксний масив)
- Структуру будуєте по одному тексту, а потім багаторазово запитуєте? (якщо багато взірців шукаєте у тексті за один прохід → Ахо-Корасік)
- Лінійних методів (КМП/хеші) недостатньо для ваших підрядкових запитів? (для простого пошуку одного взірця → КМП)
Означення суфіксного автомата
Суфіксний автомат для заданого рядка — це мінімальний DFA (детермінований скінченний автомат / детермінована скінченна машина станів), який приймає всі суфікси рядка .
Іншими словами:
- Суфіксний автомат — це орієнтований ациклічний граф. Вершини називаються станами, а ребра — переходами між станами.
- Один зі станів є початковим станом, і він має бути джерелом графа (усі інші стани досяжні з ).
- Кожен перехід позначено деяким символом. Усі переходи, що виходять зі стану, мають мати різні позначки.
- Один або декілька станів позначено як термінальні стани. Якщо ми вирушимо з початкового стану і рухатимемося переходами до термінального стану, то позначки пройдених переходів мають складати один із суфіксів рядка . Кожен суфікс рядка має бути виразним через деякий шлях із до термінального стану.
- Суфіксний автомат містить мінімальну кількість вершин серед усіх автоматів, що задовольняють описані вище умови.
Властивість підрядків
Найпростіша і найважливіша властивість суфіксного автомата полягає в тому, що він містить інформацію про всі підрядки рядка . Будь-який шлях, що починається в початковому стані , якщо записати позначки переходів, утворює підрядок рядка . І навпаки, кожен підрядок рядка відповідає певному шляху, що починається в .
Щоб спростити пояснення, будемо казати, що підрядок відповідає цьому шляху (який починається в , і позначки якого складають цей підрядок). І навпаки, будемо казати, що будь-який шлях відповідає рядку, який складають його позначки.
До стану може вести один або декілька шляхів. Тому будемо казати, що стан відповідає множині рядків, які відповідають цим шляхам.
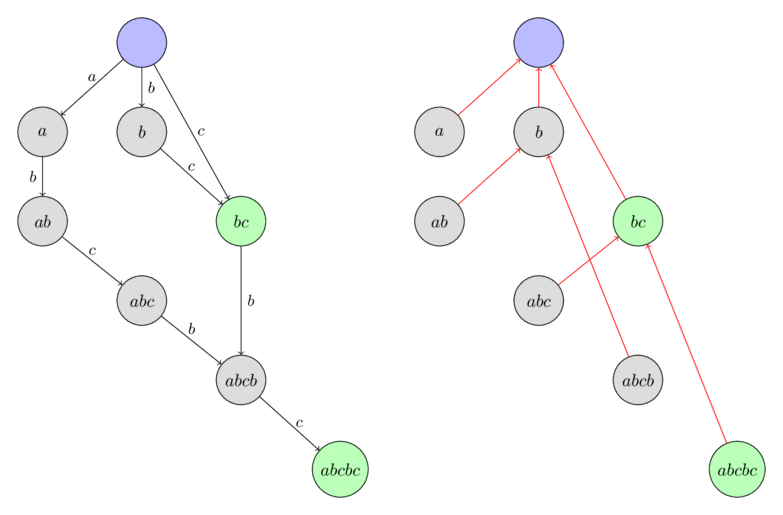
Приклади побудованих суфіксних автоматів
Тут ми наведемо кілька прикладів суфіксних автоматів для кількох простих рядків.
Початковий стан ми позначатимемо синім, а термінальні стани — зеленим.
Для рядка :

Для рядка :

Для рядка :

Для рядка :

Для рядка :

Для рядка :

Для рядка :

Побудова за лінійний час
Перш ніж описати алгоритм побудови суфіксного автомата за лінійний час, нам потрібно ввести кілька нових понять і простих доведень, які будуть дуже важливими для розуміння побудови.
Кінцеві позиції
Розглянемо будь-який непорожній підрядок рядка . Через ми позначатимемо множину всіх позицій у рядку , в яких закінчуються входження . Наприклад, для рядка маємо .
Два підрядки і ми називатимемо -еквівалентними, якщо їхні множини кінцевих позицій збігаються: . Таким чином, усі непорожні підрядки рядка можна розбити на кілька класів еквівалентності відповідно до їхніх множин .
Виявляється, що в суфіксному автоматі -еквівалентні підрядки відповідають одному й тому самому стану. Іншими словами, кількість станів у суфіксному автоматі дорівнює кількості класів еквівалентності серед усіх підрядків плюс початковий стан. Кожен стан суфіксного автомата відповідає одному або кільком підрядкам, що мають однакове значення .
Пізніше ми опишемо алгоритм побудови, користуючись цим припущенням. Тоді ми побачимо, що всі необхідні властивості суфіксного автомата, окрім мінімальності, виконуються. А мінімальність випливає з теореми Нероуда (яку ми не доводитимемо в цій статті).
Зробимо кілька важливих спостережень щодо значень :
Лема 1: Два непорожні підрядки і (де ) є -еквівалентними тоді й лише тоді, коли рядок зустрічається в лише у вигляді суфікса рядка .
Доведення очевидне. Якщо і мають однакові значення , то є суфіксом і з'являється в лише у вигляді суфікса . А якщо є суфіксом і з'являється в лише у вигляді суфікса, то значення рівні за означенням.
Лема 2: Розглянемо два непорожні підрядки і (де ). Тоді їхні множини або зовсім не перетинаються, або є підмножиною . А це залежить від того, чи є суфіксом , чи ні.
Доведення: Якщо множини і мають принаймні один спільний елемент, то рядки і обидва закінчуються в цій позиції, тобто є суфіксом . Але тоді при кожному входженні також з'являється підрядок , а це означає, що є підмножиною .
Лема 3: Розглянемо -клас еквівалентності. Відсортуємо всі підрядки цього класу за спаданням довжини. Тоді в отриманій послідовності кожен підрядок буде на один коротшим за попередній і водночас буде суфіксом попереднього. Іншими словами, в одному класі еквівалентності коротші підрядки фактично є суфіксами довших підрядків і набувають усіх можливих довжин на певному проміжку .
Доведення: Зафіксуємо деякий -клас еквівалентності. Якщо він містить лише один рядок, то лема очевидно правильна. Тепер припустимо, що кількість рядків у класі більша за один.
Згідно з Лемою 1, два різні -еквівалентні рядки завжди такі, що коротший є власним суфіксом довшого. Отже, у класі еквівалентності не може бути двох рядків однакової довжини.
Позначимо через найдовший, а через найкоротший рядок у класі еквівалентності. Згідно з Лемою 1, рядок є власним суфіксом рядка . Розглянемо тепер будь-який суфікс з довжиною в проміжку . Легко бачити, що цей суфікс також міститься в тому самому класі еквівалентності. Адже цей суфікс може з'являтися в рядку лише у вигляді суфікса (оскільки й коротший суфікс зустрічається в лише у вигляді суфікса ). Отже, згідно з Лемою 1, цей суфікс є -еквівалентним рядку .
Суфіксні посилання
Розглянемо деякий стан в автоматі. Як ми знаємо, стан відповідає класу рядків з однаковими значеннями . І якщо ми позначимо через найдовший із цих рядків, то всі інші рядки є суфіксами .
Ми також знаємо, що кілька перших суфіксів рядка (якщо розглядати суфікси в порядку спадання їхньої довжини) усі містяться в цьому класі еквівалентності, а всі інші суфікси (принаймні один — порожній суфікс) перебувають у деяких інших класах. Позначимо через найбільший такий суфікс і зробимо до нього суфіксне посилання.
Іншими словами, суфіксне посилання веде до стану, який відповідає найдовшому суфіксу рядка , що перебуває в іншому -класі еквівалентності.
Тут ми вважаємо, що початковий стан відповідає власному класу еквівалентності (що містить лише порожній рядок), і для зручності покладаємо .
Лема 4: Суфіксні посилання утворюють дерево з коренем .
Доведення: Розглянемо довільний стан . Суфіксне посилання веде до стану, що відповідає рядкам зі строго меншою довжиною (це випливає з означення суфіксних посилань і з Леми 3). Тому, рухаючись суфіксними посиланнями, ми рано чи пізно прийдемо до початкового стану , який відповідає порожньому рядку.
Лема 5: Якщо ми побудуємо дерево за допомогою множин (за правилом, що множина батьківського вузла містить множини всіх дітей як підмножини), то ця структура збігатиметься з деревом суфіксних посилань.
Доведення: Те, що ми можемо побудувати дерево за допомогою множин , випливає безпосередньо з Леми 2 (будь-які дві множини або не перетинаються, або одна міститься в іншій).
Розглянемо тепер довільний стан і його суфіксне посилання . З означення суфіксного посилання і з Леми 2 випливає, що
що разом з попередньою лемою доводить твердження: дерево суфіксних посилань по суті є деревом множин .
Ось приклад дерева суфіксних посилань у суфіксному автоматі, побудованому для рядка . Вузли позначено найдовшим підрядком із відповідного класу еквівалентності.
Підсумок
Перш ніж переходити до самого алгоритму, підсумуємо накопичені знання і введемо кілька допоміжних позначень.
- Підрядки рядка можна розбити на класи еквівалентності відповідно до їхніх кінцевих позицій .
- Суфіксний автомат складається з початкового стану , а також з одного стану для кожного -класу еквівалентності.
- Кожному стану відповідає один або декілька підрядків. Через ми позначатимемо найдовший такий рядок, а через — його довжину. Через ми позначатимемо найкоротший такий підрядок, а його довжину — через . Тоді всі рядки, що відповідають цьому стану, є різними суфіксами рядка і мають усі можливі довжини на проміжку .
- Для кожного стану суфіксне посилання визначається як посилання, що веде до стану, який відповідає суфіксу рядка довжини . Суфіксні посилання утворюють дерево з коренем у , і водночас це дерево утворює відношення включення між множинами .
- Ми можемо виразити для через суфіксне посилання так:
- Якщо ми почнемо з довільного стану і рухатимемося суфіксними посиланнями, то рано чи пізно досягнемо початкового стану . При цьому ми отримаємо послідовність неперетинних проміжків , які в об'єднанні утворюють неперервний проміжок .
Алгоритм
Тепер ми можемо перейти до самого алгоритму. Алгоритм буде онлайновим, тобто ми додаватимемо символи рядка по одному і на кожному кроці відповідно модифікуватимемо автомат.
Щоб досягти лінійного споживання пам'яті, у кожному стані ми зберігатимемо лише значення , і список переходів. Ми не будемо позначати термінальні стани (але пізніше покажемо, як розставити ці позначки після побудови суфіксного автомата).
Спочатку автомат складається з одного стану , який матиме індекс (решта станів отримають індекси ). Для зручності призначаємо йому і ( буде фіктивним, неіснуючим станом).
Тепер уся задача зводиться до реалізації процесу додавання одного символу до кінця поточного рядка. Опишемо цей процес:
-
Нехай — стан, що відповідає всьому рядку до додавання символу . (Спочатку покладаємо , і відповідно змінюватимемо на останньому кроці алгоритму.)
-
Створюємо новий стан і призначаємо йому . Значення на цей момент невідоме.
-
Тепер виконуємо таку процедуру: Починаємо зі стану . Доки немає переходу за буквою , ми додаватимемо перехід до стану і йтимемо суфіксним посиланням. Якщо в якийсь момент перехід за буквою уже існує, то ми зупиняємося і позначаємо цей стан через .
-
Якщо ми не знайшли такого стану , тобто дійшли до фіктивного стану , то ми можемо просто покласти і завершити.
-
Припустимо тепер, що ми знайшли стан , з якого існує перехід за буквою . Стан, до якого веде цей перехід, ми позначимо через .
-
Тепер маємо два випадки. Або , або ні.
-
Якщо , то ми можемо просто покласти і завершити.
-
Інакше все трохи складніше. Необхідно клонувати стан : ми створюємо новий стан , копіюємо всі дані з (суфіксне посилання й переходи), окрім значення . Покладаємо .
Після клонування ми спрямовуємо суфіксне посилання з на , а також з на clone.
Нарешті, нам потрібно пройтися зі стану назад суфіксними посиланнями, доки існує перехід за до стану , і перенаправити всі ці переходи на стан .
-
У будь-якому з трьох випадків після завершення процедури ми оновлюємо значення станом .
Якщо ми також хочемо знати, які стани є термінальними, а які ні, то можемо знайти всі термінальні стани після побудови повного суфіксного автомата для всього рядка . Для цього ми беремо стан, що відповідає всьому рядку (збережений у змінній ), і йдемо його суфіксними посиланнями, доки не досягнемо початкового стану. Усі відвідані стани ми позначимо як термінальні. Легко зрозуміти, що в такий спосіб ми позначимо саме ті стани, що відповідають усім суфіксам рядка , а це і є термінальні стани.
У наступному розділі ми детально розглянемо кожен крок і покажемо його коректність.
Тут лише зауважимо, що оскільки ми створюємо лише один або два нові стани на кожен символ , суфіксний автомат містить лінійну кількість станів.
Лінійність кількості переходів і взагалі лінійність часу роботи алгоритму менш очевидні, і їх ми доведемо після того, як доведемо коректність.
Коректність
-
Перехід ми називатимемо неперервним, якщо . Інакше, тобто коли , перехід називатимемо розривним.
Як видно з опису алгоритму, неперервні й розривні переходи приводять до різних випадків алгоритму. Неперервні переходи зафіксовані й більше ніколи не змінюються. Натомість розривні переходи можуть змінюватися, коли до рядка додаються нові букви (кінець ребра переходу може змінюватися).
-
Щоб уникнути неоднозначності, рядок, для якого було побудовано суфіксний автомат до додавання поточного символу , ми позначатимемо через .
-
Алгоритм починається зі створення нового стану , який відповідатиме всьому рядку . Зрозуміло, чому ми маємо створити новий стан. Разом із новим символом створюється новий клас еквівалентності.
-
Після створення нового стану ми проходимо суфіксними посиланнями, починаючи зі стану, що відповідає всьому рядку . Для кожного стану ми намагаємося додати перехід із символом до нового стану . Таким чином ми дописуємо до кожного суфікса рядка символ . Однак ми можемо додавати ці нові переходи лише тоді, коли вони не конфліктують із уже наявним. Тому, як тільки ми знаходимо вже наявний перехід за , ми маємо зупинитися.
-
У найпростішому випадку ми дійшли до фіктивного стану . Це означає, що ми додали перехід за до всіх суфіксів рядка . Це також означає, що символ раніше не входив до рядка . Тому суфіксне посилання має вести до стану .
-
У другому випадку ми натрапили на наявний перехід . Це означає, що ми спробували додати до машини рядок (де — суфікс рядка ), який уже існує в машині (рядок уже зустрічається як підрядок ). Оскільки ми припускаємо, що автомат для рядка побудовано правильно, новий перехід тут додавати не слід.
Однак тут є складність. До якого стану має вести суфіксне посилання зі стану ? Ми маємо зробити суфіксне посилання до стану, в якому найдовший рядок — це саме , тобто цього стану має дорівнювати . Однак можливо, що такого стану ще не існує, тобто . У цьому випадку нам доведеться створити такий стан, розщепивши стан .
-
Якщо перехід виявляється неперервним, то . У цьому випадку все просто. Ми спрямовуємо суфіксне посилання з на стан .
-
Інакше перехід є розривним, тобто . Це означає, що стан відповідає не лише суфіксу рядка довжини , а й довшим підрядкам рядка . Нам не лишається нічого іншого, окрім як розщепити стан на два підстани так, щоб перший мав довжину .
Як можна розщепити стан? Ми клонуємо стан , що дає нам стан , і покладаємо . Ми копіюємо всі переходи з до , бо не хочемо змінювати шляхи, що проходять через . Також ми встановлюємо суфіксне посилання з на ціль суфіксного посилання , а суфіксне посилання — на .
І після розщеплення стану ми встановлюємо суфіксне посилання з на .
На останньому кроці ми змінюємо деякі переходи до , перенаправляючи їх на . Які переходи ми маємо змінити? Достатньо перенаправити лише переходи, що відповідають усім суфіксам рядка (де — найдовший рядок ), тобто нам потрібно продовжувати рух суфіксними посиланнями, починаючи з вершини , доки ми не досягнемо фіктивного стану або переходу, що веде до іншого стану, ніж .
Лінійна кількість операцій
Спочатку ми одразу робимо припущення, що розмір алфавіту сталий. Якщо це не так, то про лінійну часову складність говорити не вдасться. Список переходів з однієї вершини зберігатиметься у збалансованому дереві, що дозволяє швидко виконувати операції пошуку за ключем і додавання ключів. Тому якщо ми позначимо через розмір алфавіту, то асимптотична поведінка алгоритму буде з пам'яті. Однак якщо алфавіт достатньо малий, то можна пожертвувати пам'яттю, відмовившись від збалансованих дерев, і зберігати переходи в кожній вершині як масив довжини (для швидкого пошуку за ключем) і динамічний список (для швидкого обходу всіх наявних ключів). Так ми досягаємо часової складності для алгоритму, але ціною складності пам'яті .
Отже, ми вважатимемо розмір алфавіту сталим, тобто кожну операцію пошуку переходу за символом, додавання переходу, пошуку наступного переходу — усі ці операції можна виконати за .
Якщо ми розглянемо всі частини алгоритму, то він містить три місця, в яких лінійна складність не очевидна:
- Перше місце — обхід суфіксними посиланнями зі стану із додаванням переходів із символом .
- Друге місце — копіювання переходів, коли стан клонується в новий стан .
- Третє місце — зміна переходів, що ведуть до , з перенаправленням їх на .
Ми користуємося тим фактом, що розмір суфіксного автомата (як за кількістю станів, так і за кількістю переходів) є лінійним. (Доведенням лінійності кількості станів є сам алгоритм, а доведення лінійності кількості станів наведено нижче, після реалізації алгоритму.)
Таким чином, загальна складність першого і другого місць очевидна, адже кожна операція додає лише один амортизований новий перехід до автомата.
Залишається оцінити загальну складність третього місця, в якому ми перенаправляємо переходи, що спочатку вказували на , на . Позначимо . Це суфікс рядка , і з кожною ітерацією його довжина зменшується — а отже, позиція як суфікса рядка монотонно зростає з кожною ітерацією. У цьому випадку, якщо перед першою ітерацією циклу відповідний рядок перебував на глибині () від (рахуючи глибину як кількість суфіксних посилань), то після останньої ітерації рядок буде -м суфіксним посиланням на шляху від (який стане новим значенням ).
Таким чином, кожна ітерація цього циклу призводить до того, що позиція рядка як суфікса поточного рядка монотонно зростає. Тому цей цикл не може виконатися більш ніж ітерацій, що й потрібно було довести.
Реалізація
Спочатку опишемо структуру даних, яка зберігатиме всю інформацію про конкретний перехід (, і список переходів). За потреби сюди можна додати прапорець термінального стану, а також іншу інформацію. Список переходів ми зберігатимемо у вигляді , що дозволяє нам досягти сумарно пам'яті та часу на обробку всього рядка.
- C++
- Python
- TypeScript
- Go
struct state {
int len, link;
map<char, int> next;
};
# C++ map<char,int> передаємо як звичайний dict[str,int]:
# ключі — односимвольні рядки, значення — індекси станів.
# len і link тримаємо окремими списками (st_len, st_link),
# а переходи — списком словників st_next, де st_next[v][c] = індекс.
class State:
def __init__(self):
self.len = 0
self.link = -1
self.next: dict[str, int] = {}
// C++ map<char,int> моделюємо як Map<string, number>:
// ключ — односимвольний рядок (TS не має окремого типу char).
interface State {
len: number;
link: number;
next: Map<string, number>;
}
// C++ map<char,int> у Go — це map[byte]int:
// у Go рядок індексується байтами, тож символ зручно тримати як byte.
type state struct {
length int // len — зарезервоване ім'я вбудованої функції, тому length
link int
next map[byte]int
}
Сам суфіксний автомат зберігатиметься в масиві цих структур . Ми зберігаємо поточний розмір , а також змінну — стан, що відповідає всьому рядку на цей момент.
- C++
- Python
- TypeScript
- Go
const int MAXLEN = 100000;
state st[MAXLEN * 2];
int sz, last;
# Замість статичного масиву на MAXLEN*2 використовуємо динамічний список,
# який зростає під час побудови. sz і last — глобальний стан автомата.
MAXLEN = 100000
st: list[State] = []
sz = 0
last = 0
// Замість статичного масиву використовуємо динамічний st, що зростає
// під час побудови. sz і last — поточний стан автомата.
const MAXLEN = 100000;
let st: State[] = [];
let sz = 0;
let last = 0;
// Замість статичного масиву використовуємо зріз, який нарощуємо append-ом.
const MAXLEN = 100000
var st []state
var sz, last int
Наведемо функцію, що ініціалізує суфіксний автомат (створює суфіксний автомат з одним станом).
- C++
- Python
- TypeScript
- Go
void sa_init() {
st[0].len = 0;
st[0].link = -1;
sz++;
last = 0;
}
def sa_init():
global sz, last, st
st = [State()] # початковий стан t0
st[0].len = 0
st[0].link = -1
sz = 1
last = 0
function saInit(): void {
st = [{ len: 0, link: -1, next: new Map() }]; // початковий стан t0
sz = 1;
last = 0;
}
func saInit() {
// Виділяємо ємність наперед, щоб уникнути зайвих перевиділень.
st = make([]state, 1, MAXLEN*2)
st[0].length = 0
st[0].link = -1
st[0].next = make(map[byte]int) // нульове значення map у Go — nil, тож ініціалізуємо
sz = 1
last = 0
}
І нарешті наведемо реалізацію головної функції — яка додає наступний символ до кінця поточного рядка, відповідно перебудовуючи машину.
- C++
- Python
- TypeScript
- Go
void sa_extend(char c) {
int cur = sz++;
st[cur].len = st[last].len + 1;
int p = last;
while (p != -1 && !st[p].next.count(c)) {
st[p].next[c] = cur;
p = st[p].link;
}
if (p == -1) {
st[cur].link = 0;
} else {
int q = st[p].next[c];
if (st[p].len + 1 == st[q].len) {
st[cur].link = q;
} else {
int clone = sz++;
st[clone].len = st[p].len + 1;
st[clone].next = st[q].next;
st[clone].link = st[q].link;
while (p != -1 && st[p].next[c] == q) {
st[p].next[c] = clone;
p = st[p].link;
}
st[q].link = st[cur].link = clone;
}
}
last = cur;
}
def sa_extend(c: str):
global sz, last
cur = sz
st.append(State()) # створюємо новий стан cur
sz += 1
st[cur].len = st[last].len + 1
p = last
while p != -1 and c not in st[p].next:
st[p].next[c] = cur
p = st[p].link
if p == -1:
st[cur].link = 0
else:
q = st[p].next[c]
if st[p].len + 1 == st[q].len:
st[cur].link = q
else:
clone = sz
st.append(State()) # клон стану q
sz += 1
st[clone].len = st[p].len + 1
st[clone].next = dict(st[q].next) # копія словника переходів
st[clone].link = st[q].link
while p != -1 and st[p].next.get(c) == q:
st[p].next[c] = clone
p = st[p].link
st[q].link = clone
st[cur].link = clone
last = cur
function saExtend(c: string): void {
const cur = sz++;
st.push({ len: 0, link: -1, next: new Map() }); // новий стан cur
st[cur].len = st[last].len + 1;
let p = last;
while (p !== -1 && !st[p].next.has(c)) {
st[p].next.set(c, cur);
p = st[p].link;
}
if (p === -1) {
st[cur].link = 0;
} else {
const q = st[p].next.get(c)!;
if (st[p].len + 1 === st[q].len) {
st[cur].link = q;
} else {
const clone = sz++;
st.push({ // клон стану q
len: st[p].len + 1,
link: st[q].link,
next: new Map(st[q].next), // копія переходів
});
while (p !== -1 && st[p].next.get(c) === q) {
st[p].next.set(c, clone);
p = st[p].link;
}
st[q].link = clone;
st[cur].link = clone;
}
}
last = cur;
}
func saExtend(c byte) {
cur := sz
sz++
st = append(st, state{link: -1, next: make(map[byte]int)}) // новий стан cur
st[cur].length = st[last].length + 1
p := last
for p != -1 {
if _, ok := st[p].next[c]; ok {
break
}
st[p].next[c] = cur
p = st[p].link
}
if p == -1 {
st[cur].link = 0
} else {
q := st[p].next[c]
if st[p].length+1 == st[q].length {
st[cur].link = q
} else {
clone := sz
sz++
// копіюємо переходи q у новий map (мапи у Go — посилальні)
cloneNext := make(map[byte]int, len(st[q].next))
for k, v := range st[q].next {
cloneNext[k] = v
}
st = append(st, state{
length: st[p].length + 1,
link: st[q].link,
next: cloneNext,
})
for p != -1 && st[p].next[c] == q {
st[p].next[c] = clone
p = st[p].link
}
st[q].link = clone
st[cur].link = clone
}
}
last = cur
}
Як зазначено вище, якщо пожертвувати пам'яттю (, де — розмір алфавіту), то можна досягти часу побудови машини навіть для будь-якого розміру алфавіту . Але для цього доведеться зберігати в кожному стані масив розміру (для швидкого переходу до переходу за буквою) і додатково список усіх переходів (для швидкого ітерування по переходах).
Додаткові властивості
Кількість станів
Кількість станів у суфіксному автоматі рядка довжини не перевищує (для ).
Доведенням є сам алгоритм побудови, оскільки спочатку автомат складається з одного стану, на першій і другій ітерації створюється лише один стан, а на решті кроків створюється щонайбільше стани на кожному.
Однак ми можемо також показати цю оцінку без знання алгоритму. Нагадаємо, що кількість станів дорівнює кількості різних множин . Крім того, ці множини утворюють дерево (батьківська вершина містить у своїй множині всі дочірні множини). Розглянемо це дерево і трохи його перетворимо: доки в ньому є внутрішня вершина лише з однією дитиною (а це означає, що множина дитини не містить принаймні однієї позиції з батьківської множини), ми створюємо нову дитину з множиною відсутніх позицій. Зрештою ми отримуємо дерево, в якому кожна внутрішня вершина має степінь більший за один, а кількість листків не перевищує . Тому в такому дереві не більш ніж вершин.
Цю межу кількості станів насправді можна досягти для кожного . Можливий рядок такий:
На кожній ітерації, починаючи з третьої, алгоритм розщеплюватиме стан, унаслідок чого вийде рівно станів.
Кількість переходів
Кількість переходів у суфіксному автоматі рядка довжини не перевищує (для ).
Доведемо це:
Спочатку оцінимо кількість неперервних переходів. Розглянемо кістякове дерево найдовших шляхів в автоматі, що починаються у стані . Цей каркас складатиметься лише з неперервних ребер, а тому їхня кількість менша за кількість станів, тобто не перевищує .
Тепер оцінимо кількість розривних переходів. Нехай поточний розривний перехід — це із символом . Візьмемо відповідний рядок , де рядок відповідає найдовшому шляху з початкового стану до , а — найдовшому шляху з до будь-якого термінального стану. З одного боку, кожен такий рядок для кожного неповного рядка буде різним (оскільки рядки і утворюються лише повними переходами). З іншого боку, кожен такий рядок за означенням термінальних станів буде суфіксом усього рядка . Оскільки існує лише непорожніх суфіксів , а жоден із рядків не може містити (бо весь рядок містить лише повні переходи), загальна кількість неповних переходів не перевищує .
Поєднання цих двох оцінок дає нам межу . Однак, оскільки максимальної кількості станів можна досягти лише на тесті , а цей випадок очевидно має менше за переходів, ми отримуємо точнішу межу для кількості переходів у суфіксному автоматі.
Цю межу також можна досягти рядком:
Застосування
Тут ми розглянемо деякі задачі, які можна розв'язати за допомогою суфіксного автомата. Для простоти ми вважаємо розмір алфавіту сталим, що дозволяє нам вважати складність дописування символу й обходу сталою.
Перевірка входження
Дано текст і кілька взірців . Нам потрібно перевірити, чи з'являються рядки як підрядок .
Ми будуємо суфіксний автомат тексту за часу. Щоб перевірити, чи з'являється взірець у , ми йдемо переходами, починаючи з , відповідно до символів . Якщо в якийсь момент переходу не існує, то взірець не з'являється як підрядок . Якщо ми можемо обробити в такий спосіб увесь рядок , то рядок з'являється в .
Зрозуміло, що це займе часу для кожного рядка . Більше того, цей алгоритм фактично знаходить довжину найдовшого префікса , що з'являється в тексті.
Кількість різних підрядків
Дано рядок . Потрібно обчислити кількість різних підрядків.
Побудуємо суфіксний автомат для рядка .
Кожен підрядок відповідає деякому шляху в автоматі. Тому кількість різних підрядків дорівнює кількості різних шляхів в автоматі, що починаються в .
Оскільки суфіксний автомат є орієнтованим ациклічним графом, кількість різних шляхів можна обчислити за допомогою динамічного програмування.
А саме, нехай — кількість шляхів, що починаються у стані (включно зі шляхом нульової довжини). Тоді маємо рекурсію:
Тобто можна виразити як суму відповідей для всіх кінців переходів .
Кількість різних підрядків — це значення (оскільки порожній підрядок ми не рахуємо).
Загальна часова складність:
Як альтернативу, ми можемо скористатися тим, що кожному стану відповідають підрядки довжини . Тому, з огляду на , маємо, що загальна кількість різних підрядків у стані становить .
Це лаконічно продемонстровано нижче:
- C++
- Python
- TypeScript
- Go
long long get_diff_strings(){
long long tot = 0;
for(int i = 1; i < sz; i++) {
tot += st[i].len - st[st[i].link].len;
}
return tot;
}
def get_diff_strings() -> int:
# У Python цілі необмежені, тож переповнення long long тут неактуальне.
tot = 0
for i in range(1, sz):
tot += st[i].len - st[st[i].link].len
return tot
function getDiffStrings(): bigint {
// Використовуємо bigint, бо кількість підрядків може перевищити 2^53.
let tot = 0n;
for (let i = 1; i < sz; i++) {
tot += BigInt(st[i].len - st[st[i].link].len);
}
return tot;
}
func getDiffStrings() int64 {
var tot int64
for i := 1; i < sz; i++ {
tot += int64(st[i].length - st[st[i].link].length)
}
return tot
}
Хоча це теж , цей підхід не потребує додаткової пам'яті й рекурсивних викликів, а отже, на практиці працює швидше.
Сумарна довжина всіх різних підрядків
Дано рядок . Ми хочемо обчислити сумарну довжину всіх його різних підрядків.
Розв'язок схожий на попередній, тільки тепер для частини з динамічним програмуванням необхідно розглядати дві величини: кількість різних підрядків та їхню сумарну довжину .
Як обчислювати , ми вже описали в попередній задачі. Значення можна обчислити за допомогою рекурсії:
Ми беремо відповідь кожної суміжної вершини і додаємо до неї (оскільки кожен підрядок на один символ довший, коли починається зі стану ).
І знову цю задачу можна обчислити за часу.
Як альтернативу, ми можемо знову скористатися тим, що кожному стану відповідають підрядки довжини . Оскільки і за формулою суми арифметичної прогресії (де позначає суму доданків, — перший доданок, а — останній доданок), ми можемо обчислити сумарну довжину підрядків у стані за сталий час. Потім ми підсумовуємо ці суми для кожного стану в автоматі. Це показано в коді нижче:
- C++
- Python
- TypeScript
- Go
long long get_tot_len_diff_substings() {
long long tot = 0;
for(int i = 1; i < sz; i++) {
long long shortest = st[st[i].link].len + 1;
long long longest = st[i].len;
long long num_strings = longest - shortest + 1;
long long cur = num_strings * (longest + shortest) / 2;
tot += cur;
}
return tot;
}
def get_tot_len_diff_substings() -> int:
tot = 0
for i in range(1, sz):
shortest = st[st[i].link].len + 1
longest = st[i].len
num_strings = longest - shortest + 1
# сума арифметичної прогресії; // — цілочисельне ділення
cur = num_strings * (longest + shortest) // 2
tot += cur
return tot
function getTotLenDiffSubstings(): bigint {
let tot = 0n;
for (let i = 1; i < sz; i++) {
const shortest = BigInt(st[st[i].link].len + 1);
const longest = BigInt(st[i].len);
const numStrings = longest - shortest + 1n;
// у bigint ділення / уже цілочисельне
const cur = (numStrings * (longest + shortest)) / 2n;
tot += cur;
}
return tot;
}
func getTotLenDiffSubstings() int64 {
var tot int64
for i := 1; i < sz; i++ {
shortest := int64(st[st[i].link].length + 1)
longest := int64(st[i].length)
numStrings := longest - shortest + 1
cur := numStrings * (longest + shortest) / 2
tot += cur
}
return tot
}
Цей підхід працює за часу, але експериментально працює у 20 разів швидше за версію з мемоїзованим динамічним програмуванням на випадкових рядках. Він не потребує додаткової пам'яті й рекурсії.
Лексикографічно -й підрядок
Дано рядок . Нам потрібно відповісти на кілька запитів. Для кожного заданого числа ми маємо знайти -й рядок у лексикографічно впорядкованому списку всіх підрядків.
Розв'язок цієї задачі ґрунтується на ідеї двох попередніх задач. Лексикографічно -й підрядок відповідає лексикографічно -му шляху в суфіксному автоматі. Тому, підрахувавши кількість шляхів з кожного стану, ми можемо легко шукати -й шлях, починаючи з кореня автомата.
Це займає часу на попередню обробку, а потім на кожен запит (де — відповідь на запит, а — розмір алфавіту).
Найменший циклічний зсув
Дано рядок . Ми хочемо знайти лексикографічно найменший циклічний зсув.
Ми будуємо суфіксний автомат для рядка . Тоді автомат міститиме в собі як шляхи всі циклічні зсуви рядка .
Отже, задача зводиться до пошуку лексикографічно найменшого шляху довжини , що можна зробити тривіально: ми починаємо в початковому стані й жадібно проходимо переходами з мінімальним символом.
Загальна часова складність — .
Кількість входжень
Дано текст . Нам потрібно відповісти на кілька запитів. Для кожного заданого взірця ми маємо з'ясувати, скільки разів рядок з'являється в рядку як підрядок.
Ми будуємо суфіксний автомат для тексту .
Далі робимо таку попередню обробку: для кожного стану в автоматі ми обчислюємо число , що дорівнює розміру множини . Насправді всі рядки, що відповідають одному й тому самому стану , з'являються в тексті однакову кількість разів, що дорівнює кількості позицій у множині .
Однак ми не можемо будувати множини явно, тому розглядаємо лише їхні розміри .
Щоб їх обчислити, ми робимо так. Для кожного стану, якщо його було створено не клонуванням (і якщо це не початковий стан ), ми ініціалізуємо його значенням . Потім ми пройдемося по всіх станах у порядку спадання їхньої довжини і додамо поточне значення до суфіксних посилань:
Це дає правильне значення для кожного стану.
Чому це правильно? Загальна кількість станів, отриманих не через клонування, дорівнює точно , і перші з них з'явилися, коли ми додали перші символів. Отже, для кожного з цих станів ми рахуємо відповідну позицію, на якій його було оброблено. Тому спочатку ми маємо для кожного такого стану і для всіх інших.
Потім ми застосовуємо таку операцію для кожного : . Сенс цього в тому, що якщо рядок з'являється разів, то й усі його суфікси з'являються в тих самих кінцевих позиціях, а отже, теж разів.
Чому ми не рахуємо забагато в цій процедурі (тобто не рахуємо деякі позиції двічі)? Бо ми додаємо позиції стану лише до одного іншого стану, тож не може статися, щоб один стан спрямовував свої позиції до іншого стану двічі двома різними способами.
Таким чином, ми можемо обчислити величини для всіх станів автомата за часу.
Після цього відповідь на запит — це просто значення , де — стан, що відповідає взірцю, якщо такий стан існує. Інакше відповідаємо . Відповідь на запит займає часу.
Позиція першого входження
Дано текст і кілька запитів. Для кожного рядка запиту ми хочемо знайти позицію першого входження у рядок (позицію початку ).
Ми знову будуємо суфіксний автомат. Додатково ми попередньо обчислюємо позицію для всіх станів в автоматі, тобто для кожного стану ми хочемо знайти позицію кінця першого входження. Іншими словами, ми хочемо заздалегідь знайти мінімальний елемент кожної множини (оскільки, очевидно, ми не можемо підтримувати всі множини явно).
Щоб підтримувати ці позиції , ми розширюємо функцію sa_extend().
Коли ми створюємо новий стан , ми покладаємо:
А коли ми клонуємо вершину як , ми покладаємо:
(оскільки єдиний інший варіант значення — це , який, безперечно, завеликий)
Таким чином, відповідь на запит — це просто , де — стан, що відповідає рядку . Відповідь на запит знову займає лише часу.
Усі позиції входжень
Цього разу нам потрібно вивести всі позиції входжень у рядок .
Знову будуємо суфіксний автомат для тексту . Подібно до попередньої задачі ми обчислюємо позицію для всіх станів.
Очевидно, є частиною відповіді, якщо — стан, що відповідає рядку запиту . Отже, ми врахували стан автомата, що містить . Які ще стани нам потрібно врахувати? Усі стани, що відповідають рядкам, для яких є суфіксом. Іншими словами, нам потрібно знайти всі стани, з яких можна досягти стану через суфіксні посилання.
Тому для розв'язання задачі нам потрібно зберігати для кожного стану список суфіксних посилань, що ведуть до нього. Тоді відповідь на запит міститиме всі для кожного стану, який ми можемо знайти за допомогою DFS / BFS, починаючи зі стану і користуючись лише суфіксними посиланнями.
Загалом це потребує на попередню обробку і на кожен запит, де — це розмір відповіді.
Спочатку ми спускаємося автоматом для кожного символу взірця, щоб знайти наш початковий вузол, що потребує . Потім ми застосовуємо наш прийом, який працюватиме за час , бо ми не відвідуватимемо жоден стан двічі (оскільки з кожного стану виходить лише одне суфіксне посилання, тож не може бути двох різних шляхів, що ведуть до того самого стану).
Ми лише маємо врахувати, що два різні стани можуть мати однакове значення . Це трапляється, якщо один стан було отримано клонуванням іншого. Однак це не псує складність, оскільки кожен стан може мати щонайбільше один клон.
Більше того, ми можемо також позбутися повторюваних позицій, якщо не виводитимемо позиції з клонованих станів.
Насправді стан, якого може досягти клонований стан, також досяжний з оригінального стану.
Тому, якщо ми запам'ятаємо прапорець is_cloned для кожного стану, ми можемо просто ігнорувати клоновані стани й виводити лише для всіх інших станів.
Ось кілька начерків реалізації:
- C++
- Python
- TypeScript
- Go
struct state {
...
bool is_clone;
int first_pos;
vector<int> inv_link;
};
// after constructing the automaton
for (int v = 1; v < sz; v++) {
st[st[v].link].inv_link.push_back(v);
}
// output all positions of occurrences
void output_all_occurrences(int v, int P_length) {
if (!st[v].is_clone)
cout << st[v].first_pos - P_length + 1 << endl;
for (int u : st[v].inv_link)
output_all_occurrences(u, P_length);
}
class State:
...
is_clone: bool
first_pos: int
inv_link: list[int] # обернені суфіксні посилання
# після побудови автомата
for v in range(1, sz):
st[st[v].link].inv_link.append(v)
# вивести всі позиції входжень
def output_all_occurrences(v: int, p_length: int):
if not st[v].is_clone:
print(st[v].first_pos - p_length + 1)
for u in st[v].inv_link:
output_all_occurrences(u, p_length)
interface State {
// ...
isClone: boolean;
firstPos: number;
invLink: number[]; // обернені суфіксні посилання
}
// після побудови автомата
for (let v = 1; v < sz; v++) {
st[st[v].link].invLink.push(v);
}
// вивести всі позиції входжень
function outputAllOccurrences(v: number, pLength: number): void {
if (!st[v].isClone) {
console.log(st[v].firstPos - pLength + 1);
}
for (const u of st[v].invLink) {
outputAllOccurrences(u, pLength);
}
}
type state struct {
// ...
isClone bool
firstPos int
invLink []int // обернені суфіксні посилання
}
// після побудови автомата
for v := 1; v < sz; v++ {
p := st[v].link
st[p].invLink = append(st[p].invLink, v)
}
// вивести всі позиції входжень
func outputAllOccurrences(v, pLength int) {
if !st[v].isClone {
fmt.Println(st[v].firstPos - pLength + 1)
}
for _, u := range st[v].invLink {
outputAllOccurrences(u, pLength)
}
}
Найкоротший рядок, що не зустрічається
Дано рядок і певний алфавіт. Нам потрібно знайти рядок найменшої довжини, який не зустрічається в .
Ми застосуємо динамічне програмування на суфіксному автоматі, побудованому для рядка .
Нехай — відповідь для вузла , тобто ми вже обробили частину підрядка, наразі перебуваємо у стані і хочемо знайти найменшу кількість символів, які треба додати, щоб знайти неіснуючий перехід. Обчислення дуже просте. Якщо немає переходу хоча б за одним символом алфавіту, то . Інакше одного символу недостатньо, і тому нам потрібно взяти мінімум з усіх відповідей усіх переходів:
Відповіддю до задачі буде , а сам рядок можна відновити за допомогою обчисленого масиву .
Найдовший спільний підрядок двох рядків
Дано два рядки і . Нам потрібно знайти найдовший спільний підрядок, тобто такий рядок , що з'являється як підрядок у і також у .
Ми будуємо суфіксний автомат для рядка .
Тепер ми візьмемо рядок і для кожного префікса шукатимемо найдовший суфікс цього префікса в . Іншими словами, для кожної позиції в рядку ми хочемо знайти найдовший спільний підрядок і , що закінчується в цій позиції.
Для цього ми використаємо дві змінні — поточний стан і поточну довжину . Ці дві змінні описуватимуть поточну зіставлену частину: її довжину і стан, що їй відповідає.
Спочатку і , тобто зіставлення порожнє.
Тепер опишемо, як ми можемо додати символ і перерахувати для нього відповідь.
- Якщо з є перехід за символом , то ми просто йдемо цим переходом і збільшуємо на один.
- Якщо такого переходу немає, ми маємо скоротити поточну зіставлену частину, що означає необхідність піти суфіксним посиланням: . Водночас поточну довжину треба скоротити. Очевидно, нам потрібно покласти , оскільки після проходження суфіксним посиланням ми опиняємося у стані, найдовший відповідний рядок якого є підрядком.
- Якщо переходу за потрібним символом усе ще немає, ми повторюємо і знову йдемо суфіксним посиланням і зменшуємо , доки не знайдемо перехід або не досягнемо фіктивного стану (що означає, що символ зовсім не з'являється в , тож ми покладаємо ).
Відповіддю до задачі буде максимум усіх значень .
Складність цієї частини — , оскільки за один крок ми можемо або збільшити на один, або зробити кілька проходів суфіксними посиланнями, кожен з яких зрештою зменшує значення .
Реалізація:
- C++
- Python
- TypeScript
- Go
string lcs (string S, string T) {
sa_init();
for (int i = 0; i < S.size(); i++)
sa_extend(S[i]);
int v = 0, l = 0, best = 0, bestpos = 0;
for (int i = 0; i < T.size(); i++) {
while (v && !st[v].next.count(T[i])) {
v = st[v].link ;
l = st[v].len;
}
if (st[v].next.count(T[i])) {
v = st [v].next[T[i]];
l++;
}
if (l > best) {
best = l;
bestpos = i;
}
}
return T.substr(bestpos - best + 1, best);
}
def lcs(s: str, t: str) -> str:
sa_init()
for ch in s:
sa_extend(ch)
v = l = best = bestpos = 0
for i in range(len(t)):
# доки немає переходу за t[i], спускаємось суфіксним посиланням
while v and t[i] not in st[v].next:
v = st[v].link
l = st[v].len
if t[i] in st[v].next:
v = st[v].next[t[i]]
l += 1
if l > best:
best = l
bestpos = i
return t[bestpos - best + 1: bestpos + 1]
function lcs(s: string, t: string): string {
saInit();
for (const ch of s) {
saExtend(ch);
}
let v = 0, l = 0, best = 0, bestpos = 0;
for (let i = 0; i < t.length; i++) {
// доки немає переходу за t[i], спускаємось суфіксним посиланням
while (v && !st[v].next.has(t[i])) {
v = st[v].link;
l = st[v].len;
}
if (st[v].next.has(t[i])) {
v = st[v].next.get(t[i])!;
l++;
}
if (l > best) {
best = l;
bestpos = i;
}
}
return t.substring(bestpos - best + 1, bestpos + 1);
}
func lcs(s, t string) string {
saInit()
for i := 0; i < len(s); i++ {
saExtend(s[i])
}
v, l, best, bestpos := 0, 0, 0, 0
for i := 0; i < len(t); i++ {
c := t[i]
// доки немає переходу за c, спускаємось суфіксним посиланням
for v != 0 {
if _, ok := st[v].next[c]; ok {
break
}
v = st[v].link
l = st[v].length
}
if nv, ok := st[v].next[c]; ok {
v = nv
l++
}
if l > best {
best = l
bestpos = i
}
}
return t[bestpos-best+1 : bestpos+1]
}
Найдовший спільний підрядок кількох рядків
Задано рядків . Нам потрібно знайти найдовший спільний підрядок, тобто такий рядок , що з'являється як підрядок у кожному рядку .
Ми об'єднуємо всі рядки в один великий рядок , розділяючи рядки спеціальними символами (по одному на кожен рядок):
Потім ми будуємо суфіксний автомат для рядка .
Тепер нам потрібно знайти в машині рядок, який міститься в усіх рядках , і це можна зробити за допомогою спеціально доданих символів. Зауважимо, що якщо підрядок входить до деякого рядка , то в суфіксному автоматі існує шлях, що починається з цього підрядка, містить символ і не містить інших символів .
Таким чином, нам потрібно обчислити досяжність, яка для кожного стану машини й кожного символу показує, чи існує такий шлях. Це легко обчислити за допомогою DFS чи BFS і динамічного програмування. Після цього відповіддю до задачі буде рядок для стану , з якого існували шляхи для всіх спеціальних символів.