Друге за вагою мінімальне кістякове дерево
Мінімальне кістякове дерево — це дерево заданого графа , яке з'єднує всі вершини графа й має найменшу суму ваг усіх ребер серед усіх можливих кістякових дерев. Друге за вагою мінімальне кістякове дерево — це кістякове дерево, яке має другу за величиною найменшу суму ваг усіх ребер серед усіх можливих кістякових дерев графа .
- Потрібне саме друге за вагою кістякове дерево (а не мінімальне)? (якщо потрібне просто мінімальне → Крускал)
- Уже вмієш будувати MST і готовий зробити заміну одного ребра?
- Для швидкого варіанта через цикли доступний LCA з двійковим підйомом для пошуку найважчого ребра на шляху?
Спостереження
Нехай — мінімальне кістякове дерево графа . Можна помітити, що друге за вагою мінімальне кістякове дерево відрізняється від заміною лише одного ребра. (Доведення цього твердження дивіться в задачі 23-1 тут).
Отже, нам потрібно знайти ребро , якого немає в , і замінити ним ребро з (нехай це буде ) так, щоб новий граф був кістяковим деревом, а різниця ваг () була мінімальною.
Використання алгоритму Краскала
Ми можемо спочатку знайти MST за допомогою алгоритму Краскала, а потім просто спробувати вилучити з нього одне ребро й замінити його іншим.
- Сортуємо ребра за , потім знаходимо MST за допомогою алгоритму Краскала за .
- Для кожного ребра в MST (у ньому буде ребро) тимчасово виключаємо його зі списку ребер, щоб його не можна було обрати.
- Потім знову намагаємося знайти MST за , використовуючи решту ребер.
- Робимо це для всіх ребер MST і беремо найкраще з усіх.
Зауваження: на кроці 3 нам не потрібно сортувати ребра знову.
Отже, загальна часова складність становитиме = .
Зведення до задачі про найнижчого спільного предка (LCA)
У попередньому підході ми перебирали всі можливості вилучення одного ребра MST. Тут ми зробимо все навпаки. Ми спробуємо додати кожне ребро, якого ще немає в MST.
- Сортуємо ребра за , потім знаходимо MST за допомогою алгоритму Краскала за .
- Для кожного ребра , якого ще немає в MST, тимчасово додаємо його до MST, утворюючи цикл. Цикл проходитиме через LCA.
- Знаходимо ребро з максимальною вагою в циклі, яке не дорівнює , рухаючись по батьках вершин ребра вгору до LCA.
- Тимчасово вилучаємо , утворюючи нове кістякове дерево.
- Обчислюємо різницю ваг і запам'ятовуємо її разом зі зміненим ребром.
- Повторюємо крок 2 для всіх інших ребер і повертаємо кістякове дерево з найменшою різницею ваг порівняно з MST.
Часова складність алгоритму залежить від того, як ми обчислюємо значення — ребра з максимальною вагою на кроці 2 цього алгоритму. Один зі способів ефективно обчислити їх за — звести задачу до задачі про найнижчого спільного предка (LCA).
Ми виконаємо попередню обробку для LCA, підвісивши MST за корінь, а також обчислимо максимальні ваги ребер для кожної вершини на шляхах до її предків. Це можна зробити за допомогою двійкового підйому для LCA.
Підсумкова часова складність цього підходу — .
Наприклад:
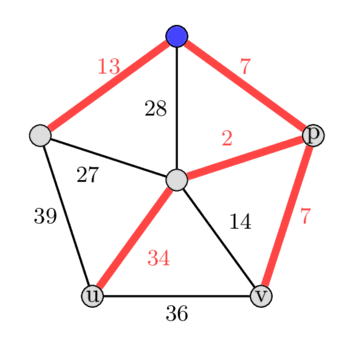
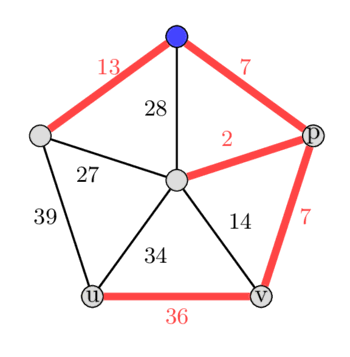
На зображенні зліва — MST, а справа — друге за вагою MST.
У заданому графі припустимо, що ми підвісили MST за синю вершину вгорі, а потім запускаємо наш алгоритм, починаючи з вибору ребер, яких немає в MST. Нехай першим обраним ребром буде ребро з вагою 36. Додавання цього ребра до дерева утворює цикл 36 - 7 - 2 - 34.
Тепер ми знайдемо ребро з максимальною вагою в цьому циклі, знайшовши . Ми обчислюємо ребро з максимальною вагою на шляхах від до та від до . Зауваження: у деяких випадках може також дорівнювати або . У цьому прикладі ми отримаємо ребро з вагою 34 як ребро з максимальною вагою в циклі. Вилучивши це ребро, ми отримуємо нове кістякове дерево, що має різницю ваг лише 2.
Зробивши це також з усіма іншими ребрами, які не є частиною початкового MST, ми бачимо, що це кістякове дерево було також другим за вагою кістяковим деревом загалом. Вибір ребра з вагою 14 збільшить вагу дерева на 7, вибір ребра з вагою 27 збільшує її на 14, вибір ребра з вагою 28 збільшує її на 21, а вибір ребра з вагою 39 збільшить вагу дерева на 5.
Реалізація
- C++
- Python
- TypeScript
- Go
struct edge {
int s, e, w, id;
bool operator<(const struct edge& other) { return w < other.w; }
};
typedef struct edge Edge;
const int N = 2e5 + 5;
long long res = 0, ans = 1e18;
int n, m, a, b, w, id, l = 21;
vector<Edge> edges;
vector<int> h(N, 0), parent(N, -1), size(N, 0), present(N, 0);
vector<vector<pair<int, int>>> adj(N), dp(N, vector<pair<int, int>>(l));
vector<vector<int>> up(N, vector<int>(l, -1));
pair<int, int> combine(pair<int, int> a, pair<int, int> b) {
vector<int> v = {a.first, a.second, b.first, b.second};
int topTwo = -3, topOne = -2;
for (int c : v) {
if (c > topOne) {
topTwo = topOne;
topOne = c;
} else if (c > topTwo && c < topOne) {
topTwo = c;
}
}
return {topOne, topTwo};
}
void dfs(int u, int par, int d) {
h[u] = 1 + h[par];
up[u][0] = par;
dp[u][0] = {d, -1};
for (auto v : adj[u]) {
if (v.first != par) {
dfs(v.first, u, v.second);
}
}
}
pair<int, int> lca(int u, int v) {
pair<int, int> ans = {-2, -3};
if (h[u] < h[v]) {
swap(u, v);
}
for (int i = l - 1; i >= 0; i--) {
if (h[u] - h[v] >= (1 << i)) {
ans = combine(ans, dp[u][i]);
u = up[u][i];
}
}
if (u == v) {
return ans;
}
for (int i = l - 1; i >= 0; i--) {
if (up[u][i] != -1 && up[v][i] != -1 && up[u][i] != up[v][i]) {
ans = combine(ans, combine(dp[u][i], dp[v][i]));
u = up[u][i];
v = up[v][i];
}
}
ans = combine(ans, combine(dp[u][0], dp[v][0]));
return ans;
}
int main(void) {
cin >> n >> m;
for (int i = 1; i <= n; i++) {
parent[i] = i;
size[i] = 1;
}
for (int i = 1; i <= m; i++) {
cin >> a >> b >> w; // нумерація з 1
edges.push_back({a, b, w, i - 1});
}
sort(edges.begin(), edges.end());
for (int i = 0; i <= m - 1; i++) {
a = edges[i].s;
b = edges[i].e;
w = edges[i].w;
id = edges[i].id;
if (unite_set(a, b)) {
adj[a].emplace_back(b, w);
adj[b].emplace_back(a, w);
present[id] = 1;
res += w;
}
}
dfs(1, 0, 0);
for (int i = 1; i <= l - 1; i++) {
for (int j = 1; j <= n; ++j) {
if (up[j][i - 1] != -1) {
int v = up[j][i - 1];
up[j][i] = up[v][i - 1];
dp[j][i] = combine(dp[j][i - 1], dp[v][i - 1]);
}
}
}
for (int i = 0; i <= m - 1; i++) {
id = edges[i].id;
w = edges[i].w;
if (!present[id]) {
auto rem = lca(edges[i].s, edges[i].e);
if (rem.first != w) {
if (ans > res + w - rem.first) {
ans = res + w - rem.first;
}
} else if (rem.second != -1) {
if (ans > res + w - rem.second) {
ans = res + w - rem.second;
}
}
}
}
cout << ans << "\n";
return 0;
}
import sys
from typing import List, Tuple
INF = 1 << 62
LOG = 21 # відповідає l = 21 у C++
def combine(a: Tuple[int, int], b: Tuple[int, int]) -> Tuple[int, int]:
# дві найбільші ваги серед двох пар (перша, друга) максимальних ваг
top_one, top_two = -2, -3
for c in (a[0], a[1], b[0], b[1]):
if c > top_one:
top_two = top_one
top_one = c
elif top_two < c < top_one:
top_two = c
return (top_one, top_two)
def solve() -> int:
data = sys.stdin.buffer.read().split()
it = iter(data)
n = int(next(it))
m = int(next(it))
# ребра: (вага, s, e, id); нумерація з 1
edges: List[Tuple[int, int, int, int]] = []
for i in range(m):
a = int(next(it))
b = int(next(it))
w = int(next(it))
edges.append((w, a, b, i))
h = [0] * (n + 1)
parent = list(range(n + 1))
size = [1] * (n + 1)
present = [0] * m
adj: List[List[Tuple[int, int]]] = [[] for _ in range(n + 1)]
up = [[-1] * LOG for _ in range(n + 1)]
dp = [[(-1, -1)] * LOG for _ in range(n + 1)]
def find_set(v: int) -> int:
# ітеративний пошук кореня зі стисканням шляху
root = v
while parent[root] != root:
root = parent[root]
while parent[v] != root:
parent[v], v = root, parent[v]
return root
def unite_set(a: int, b: int) -> bool:
a, b = find_set(a), find_set(b)
if a == b:
return False
if size[a] < size[b]:
a, b = b, a
parent[b] = a
size[a] += size[b]
return True
# будуємо MST алгоритмом Краскала
edges.sort()
res = 0
for w, a, b, eid in edges:
if unite_set(a, b):
adj[a].append((b, w))
adj[b].append((a, w))
present[eid] = 1
res += w
# Ітеративний DFS замість рекурсії: глибина дерева може сягати n, тому
# рекурсивний обхід впав би на CPython (типовий ліміт стека ~1000).
# Рекурсивний варіант вимагав би sys.setrecursionlimit(n + 10).
# Підвішуємо за вершину 1 (батько 0, як dfs(1, 0, 0) у C++).
stack = [(1, 0, 0)]
while stack:
u, par, d = stack.pop()
h[u] = 1 + h[par]
up[u][0] = par
dp[u][0] = (d, -1)
for v, vw in adj[u]:
if v != par:
stack.append((v, u, vw))
# таблиця двійкового підйому
for i in range(1, LOG):
for j in range(1, n + 1):
prev = up[j][i - 1]
if prev != -1:
up[j][i] = up[prev][i - 1]
dp[j][i] = combine(dp[j][i - 1], dp[prev][i - 1])
def lca(u: int, v: int) -> Tuple[int, int]:
ans = (-2, -3)
if h[u] < h[v]:
u, v = v, u
for i in range(LOG - 1, -1, -1):
if h[u] - h[v] >= (1 << i):
ans = combine(ans, dp[u][i])
u = up[u][i]
if u == v:
return ans
for i in range(LOG - 1, -1, -1):
if up[u][i] != -1 and up[v][i] != -1 and up[u][i] != up[v][i]:
ans = combine(ans, combine(dp[u][i], dp[v][i]))
u = up[u][i]
v = up[v][i]
ans = combine(ans, combine(dp[u][0], dp[v][0]))
return ans
ans = INF
for w, a, b, eid in edges:
if not present[eid]:
rem = lca(a, b)
if rem[0] != w:
ans = min(ans, res + w - rem[0])
elif rem[1] != -1:
ans = min(ans, res + w - rem[1])
return ans
if __name__ == "__main__":
print(solve())
const INF = Number.MAX_SAFE_INTEGER;
const LOG = 21; // відповідає l = 21 у C++
type Pair = [number, number];
// дві найбільші ваги серед двох пар (перша, друга) максимальних ваг
function combine(a: Pair, b: Pair): Pair {
let topOne = -2;
let topTwo = -3;
for (const c of [a[0], a[1], b[0], b[1]]) {
if (c > topOne) {
topTwo = topOne;
topOne = c;
} else if (c > topTwo && c < topOne) {
topTwo = c;
}
}
return [topOne, topTwo];
}
function solve(input: string): number {
const data = input.split(/\s+/).filter((s) => s.length > 0).map(Number);
let p = 0;
const n = data[p++];
const m = data[p++];
// ребра: {w, s, e, id}; нумерація з 1
const edges: { w: number; s: number; e: number; id: number }[] = [];
for (let i = 0; i < m; i++) {
const a = data[p++];
const b = data[p++];
const w = data[p++];
edges.push({ w, s: a, e: b, id: i });
}
const h = new Array<number>(n + 1).fill(0);
const parent = new Array<number>(n + 1);
const size = new Array<number>(n + 1).fill(1);
for (let i = 0; i <= n; i++) parent[i] = i;
const present = new Array<number>(m).fill(0);
const adj: Array<Array<[number, number]>> = Array.from({ length: n + 1 }, () => []);
const up: number[][] = Array.from({ length: n + 1 }, () => new Array<number>(LOG).fill(-1));
const dp: Pair[][] = Array.from({ length: n + 1 }, () =>
Array.from({ length: LOG }, () => [-1, -1] as Pair),
);
// DSU з ітеративним пошуком кореня та стисканням шляху
function findSet(v: number): number {
let root = v;
while (parent[root] !== root) root = parent[root];
while (parent[v] !== root) {
const next = parent[v];
parent[v] = root;
v = next;
}
return root;
}
function uniteSet(a: number, b: number): boolean {
a = findSet(a);
b = findSet(b);
if (a === b) return false;
if (size[a] < size[b]) [a, b] = [b, a];
parent[b] = a;
size[a] += size[b];
return true;
}
// MST алгоритмом Краскала
edges.sort((x, y) => x.w - y.w);
let res = 0;
for (const e of edges) {
if (uniteSet(e.s, e.e)) {
adj[e.s].push([e.e, e.w]);
adj[e.e].push([e.s, e.w]);
present[e.id] = 1;
res += e.w;
}
}
// Ітеративний DFS замість рекурсії (глибина дерева може сягати n).
// Підвішуємо за вершину 1 (батько 0, як dfs(1, 0, 0) у C++).
const stack: Array<[number, number, number]> = [[1, 0, 0]];
while (stack.length > 0) {
const [u, par, d] = stack.pop()!;
h[u] = 1 + h[par];
up[u][0] = par;
dp[u][0] = [d, -1];
for (const [v, vw] of adj[u]) {
if (v !== par) stack.push([v, u, vw]);
}
}
// таблиця двійкового підйому
for (let i = 1; i < LOG; i++) {
for (let j = 1; j <= n; j++) {
const prev = up[j][i - 1];
if (prev !== -1) {
up[j][i] = up[prev][i - 1];
dp[j][i] = combine(dp[j][i - 1], dp[prev][i - 1]);
}
}
}
function lca(u: number, v: number): Pair {
let ans: Pair = [-2, -3];
if (h[u] < h[v]) [u, v] = [v, u];
for (let i = LOG - 1; i >= 0; i--) {
if (h[u] - h[v] >= 1 << i) {
ans = combine(ans, dp[u][i]);
u = up[u][i];
}
}
if (u === v) return ans;
for (let i = LOG - 1; i >= 0; i--) {
if (up[u][i] !== -1 && up[v][i] !== -1 && up[u][i] !== up[v][i]) {
ans = combine(ans, combine(dp[u][i], dp[v][i]));
u = up[u][i];
v = up[v][i];
}
}
ans = combine(ans, combine(dp[u][0], dp[v][0]));
return ans;
}
let ans = INF;
for (const e of edges) {
if (!present[e.id]) {
const rem = lca(e.s, e.e);
if (rem[0] !== e.w) {
ans = Math.min(ans, res + e.w - rem[0]);
} else if (rem[1] !== -1) {
ans = Math.min(ans, res + e.w - rem[1]);
}
}
}
return ans;
}
const input = require("fs").readFileSync(0, "utf8");
console.log(solve(input));
package main
import (
"bufio"
"fmt"
"os"
"sort"
)
const (
inf = int64(1) << 62
LOG = 21 // відповідає l = 21 у C++
)
type pair struct{ first, second int }
// дві найбільші ваги серед двох пар (перша, друга) максимальних ваг
func combine(a, b pair) pair {
topOne, topTwo := -2, -3
for _, c := range []int{a.first, a.second, b.first, b.second} {
if c > topOne {
topTwo = topOne
topOne = c
} else if c > topTwo && c < topOne {
topTwo = c
}
}
return pair{topOne, topTwo}
}
type edge struct{ w, s, e, id int }
func main() {
reader := bufio.NewReader(os.Stdin)
var n, m int
fmt.Fscan(reader, &n, &m)
// ребра; нумерація з 1
edges := make([]edge, m)
for i := 0; i < m; i++ {
var a, b, w int
fmt.Fscan(reader, &a, &b, &w)
edges[i] = edge{w: w, s: a, e: b, id: i}
}
h := make([]int, n+1)
parent := make([]int, n+1)
size := make([]int, n+1)
for i := 0; i <= n; i++ {
parent[i] = i
size[i] = 1
}
present := make([]int, m)
adj := make([][]pair, n+1) // pair{first: сусід, second: вага}
up := make([][]int, n+1)
dp := make([][]pair, n+1)
for i := 0; i <= n; i++ {
up[i] = make([]int, LOG)
dp[i] = make([]pair, LOG)
for j := 0; j < LOG; j++ {
up[i][j] = -1
dp[i][j] = pair{-1, -1}
}
}
// DSU з ітеративним пошуком кореня та стисканням шляху
var findSet func(v int) int
findSet = func(v int) int {
root := v
for parent[root] != root {
root = parent[root]
}
for parent[v] != root {
parent[v], v = root, parent[v]
}
return root
}
uniteSet := func(a, b int) bool {
a, b = findSet(a), findSet(b)
if a == b {
return false
}
if size[a] < size[b] {
a, b = b, a
}
parent[b] = a
size[a] += size[b]
return true
}
// MST алгоритмом Краскала
sort.Slice(edges, func(i, j int) bool { return edges[i].w < edges[j].w })
var res int64 = 0
for _, e := range edges {
if uniteSet(e.s, e.e) {
adj[e.s] = append(adj[e.s], pair{e.e, e.w})
adj[e.e] = append(adj[e.e], pair{e.s, e.w})
present[e.id] = 1
res += int64(e.w)
}
}
// Ітеративний DFS замість рекурсії (глибина дерева може сягати n).
// Підвішуємо за вершину 1 (батько 0, як dfs(1, 0, 0) у C++).
type frame struct{ u, par, d int }
stack := []frame{{1, 0, 0}}
for len(stack) > 0 {
top := stack[len(stack)-1]
stack = stack[:len(stack)-1]
h[top.u] = 1 + h[top.par]
up[top.u][0] = top.par
dp[top.u][0] = pair{top.d, -1}
for _, v := range adj[top.u] {
if v.first != top.par {
stack = append(stack, frame{v.first, top.u, v.second})
}
}
}
// таблиця двійкового підйому
for i := 1; i < LOG; i++ {
for j := 1; j <= n; j++ {
prev := up[j][i-1]
if prev != -1 {
up[j][i] = up[prev][i-1]
dp[j][i] = combine(dp[j][i-1], dp[prev][i-1])
}
}
}
lca := func(u, v int) pair {
ans := pair{-2, -3}
if h[u] < h[v] {
u, v = v, u
}
for i := LOG - 1; i >= 0; i-- {
if h[u]-h[v] >= (1 << i) {
ans = combine(ans, dp[u][i])
u = up[u][i]
}
}
if u == v {
return ans
}
for i := LOG - 1; i >= 0; i-- {
if up[u][i] != -1 && up[v][i] != -1 && up[u][i] != up[v][i] {
ans = combine(ans, combine(dp[u][i], dp[v][i]))
u = up[u][i]
v = up[v][i]
}
}
ans = combine(ans, combine(dp[u][0], dp[v][0]))
return ans
}
ans := inf
for _, e := range edges {
if present[e.id] == 0 {
rem := lca(e.s, e.e)
if rem.first != e.w {
if cand := res + int64(e.w) - int64(rem.first); cand < ans {
ans = cand
}
} else if rem.second != -1 {
if cand := res + int64(e.w) - int64(rem.second); cand < ans {
ans = cand
}
}
}
}
fmt.Println(ans)
}
Джерела
- Competitive Programming-3, by Steven Halim
- web.mit.edu