Найнижчий спільний предок — алгоритм Фарах-Колтона–Бендера
Нехай — дерево. Для кожного запиту виду ми хочемо знайти найнижчого спільного предка вершин і , тобто хочемо знайти таку вершину , яка лежить на шляху від до кореня та на шляху від до кореня, а якщо таких вершин декілька, то ми обираємо ту, що найдальша від кореня. Іншими словами, шукана вершина — це найнижчий предок і . Зокрема, якщо є предком , то і є їхнім найнижчим спільним предком.
Алгоритм, який буде описано в цій статті, розробили Фарах-Колтон і Бендер. Він асимптотично оптимальний.
- Потрібні теоретично оптимальні на запит LCA при лише передобчисленні (онлайн, дуже багато запитів)? (якщо запити відомі заздалегідь, простіший вибір → офлайн Тар'ян)
- Ви готові до складнішої реалізації заради цієї асимптотики? (якщо хочете простіший онлайн-метод і вас влаштовує на запит → двійкові підйоми)
- Задачу справді можна звести до RMQ на масиві висот ейлерового обходу, де сусідні елементи відрізняються рівно на одиницю (це ключова умова методу)?
Алгоритм
Ми скористаємося класичним зведенням задачі LCA до задачі RMQ. Ми обходимо всі вершини дерева за допомогою DFS і зберігаємо масив із усіма відвіданими вершинами та висотами цих вершин. LCA двох вершин і — це вершина між входженнями і в обході, яка має найменшу висоту.
На наступному малюнку ви можете бачити один із можливих ейлерових обходів графа, а в списку нижче — відвідані вершини та їхні висоти.
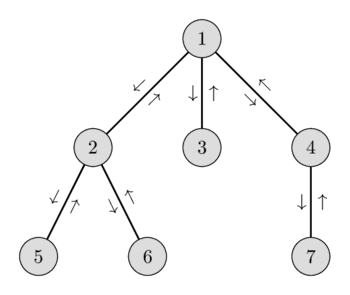
Докладніше про це зведення можна прочитати у статті Найнижчий спільний предок. У тій статті мінімум на відрізку знаходили або кореневим розбиттям за , або за за допомогою дерева відрізків. У цій статті ми розглянемо, як можна розв'язувати задані запити мінімуму на відрізку за , причому попередні обчислення займатимуть лише .
Зауважимо, що зведена задача RMQ дуже специфічна: будь-які два сусідні елементи масиву відрізняються рівно на одиницю (адже елементи масиву — це не що інше, як висоти вершин, відвіданих у порядку обходу, і ми або спускаємося до нащадка, тоді наступний елемент на одиницю більший, або повертаємося до предка, тоді наступний елемент на одиницю менший). Алгоритм Фарах-Колтона–Бендера описує розв'язок саме цієї спеціалізованої задачі RMQ.
Позначмо через масив, на якому ми хочемо виконувати запити мінімуму на відрізку. А буде розміром .
Існує проста структура даних, якою ми можемо скористатися для розв'язання задачі RMQ з попередніми обчисленнями за і на кожен запит: розріджена таблиця. Ми створюємо таблицю , де кожен елемент дорівнює мінімуму на проміжку . Очевидно, що , а отже, розмір розрідженої таблиці буде . Цю таблицю легко побудувати за , якщо помітити, що .
Як же ми можемо відповісти на запит RMQ за за допомогою цієї структури даних? Нехай отриманий запит — це , тоді відповідь — , де — найбільший показник степеня такий, що не перевищує довжини відрізка . Дійсно, ми можемо взяти відрізок і покрити його двома сегментами довжини — один починається в , а інший закінчується в . Ці сегменти перекриваються, але це не заважає нашому обчисленню. Щоб справді досягти часової складності на запит, нам потрібно знати значення для всіх можливих довжин від до . Але це легко обчислити заздалегідь.
Тепер ми хочемо покращити складність попередніх обчислень до .
Ми розбиваємо масив на блоки розміру , де — логарифм за основою 2. Для кожного блоку ми обчислюємо мінімальний елемент і зберігаємо їх у масиві . має розмір . Ми будуємо розріджену таблицю з масиву . Її розмір і часова складність будуть:
Тепер нам залишається лише навчитися швидко відповідати на запити мінімуму на відрізку всередині кожного блоку. Насправді, якщо отриманий запит мінімуму на відрізку — це і та лежать у різних блоках, то відповідь — це мінімум таких трьох значень: мінімум суфікса блоку , що починається в , мінімум префікса блоку , що закінчується в , і мінімум блоків між ними. Мінімум блоків між ними можна обчислити за за допомогою розрідженої таблиці. Отже, нам залишаються лише запити мінімуму на відрізку всередині блоків.
Тут ми скористаємося властивістю масиву. Пам'ятаймо, що значення в масиві — які є просто значеннями висот у дереві — завжди відрізняються на одиницю. Якщо ми приберемо перший елемент блоку і віднімемо його від кожного іншого елемента блоку, то кожен блок можна задати послідовністю довжини , що складається з чисел і . Оскільки ці блоки такі маленькі, існує лише небагато різних можливих послідовностей. Кількість можливих послідовностей становить:
Отже, кількість різних блоків — , а тому ми можемо обчислити заздалегідь результати запитів мінімуму на відрізку всередині всіх різних блоків за . Для реалізації ми можемо охарактеризувати блок бітовою маскою довжини (яка вміститься у стандартний int) і зберігати індекс мінімуму в масиві розміру .
Отже, ми навчилися обчислювати заздалегідь запити мінімуму на відрізку всередині кожного блоку, а також запити мінімуму на відрізку над діапазоном блоків — і все це за .
З цими попередніми обчисленнями ми можемо відповісти на кожен запит за , скориставшись щонайбільше чотирма заздалегідь обчисленими значеннями: мінімумом блоку, що містить l, мінімумом блоку, що містить r, і двома мінімумами перекривних сегментів блоків між ними.
Реалізація
- C++
- Python
- TypeScript
- Go
int n;
vector<vector<int>> adj;
int block_size, block_cnt;
vector<int> first_visit;
vector<int> euler_tour;
vector<int> height;
vector<int> log_2;
vector<vector<int>> st;
vector<vector<vector<int>>> blocks;
vector<int> block_mask;
void dfs(int v, int p, int h) {
first_visit[v] = euler_tour.size();
euler_tour.push_back(v);
height[v] = h;
for (int u : adj[v]) {
if (u == p)
continue;
dfs(u, v, h + 1);
euler_tour.push_back(v);
}
}
int min_by_h(int i, int j) {
return height[euler_tour[i]] < height[euler_tour[j]] ? i : j;
}
void precompute_lca(int root) {
// отримуємо ейлерів обхід та індекси перших входжень
first_visit.assign(n, -1);
height.assign(n, 0);
euler_tour.reserve(2 * n);
dfs(root, -1, 0);
// заздалегідь обчислюємо всі значення логарифма
int m = euler_tour.size();
log_2.reserve(m + 1);
log_2.push_back(-1);
for (int i = 1; i <= m; i++)
log_2.push_back(log_2[i / 2] + 1);
block_size = max(1, log_2[m] / 2);
block_cnt = (m + block_size - 1) / block_size;
// заздалегідь обчислюємо мінімум кожного блоку та будуємо розріджену таблицю
st.assign(block_cnt, vector<int>(log_2[block_cnt] + 1));
for (int i = 0, j = 0, b = 0; i < m; i++, j++) {
if (j == block_size)
j = 0, b++;
if (j == 0 || min_by_h(i, st[b][0]) == i)
st[b][0] = i;
}
for (int l = 1; l <= log_2[block_cnt]; l++) {
for (int i = 0; i < block_cnt; i++) {
int ni = i + (1 << (l - 1));
if (ni >= block_cnt)
st[i][l] = st[i][l-1];
else
st[i][l] = min_by_h(st[i][l-1], st[ni][l-1]);
}
}
// заздалегідь обчислюємо маску для кожного блоку
block_mask.assign(block_cnt, 0);
for (int i = 0, j = 0, b = 0; i < m; i++, j++) {
if (j == block_size)
j = 0, b++;
if (j > 0 && (i >= m || min_by_h(i - 1, i) == i - 1))
block_mask[b] += 1 << (j - 1);
}
// заздалегідь обчислюємо RMQ для кожного унікального блоку
int possibilities = 1 << (block_size - 1);
blocks.resize(possibilities);
for (int b = 0; b < block_cnt; b++) {
int mask = block_mask[b];
if (!blocks[mask].empty())
continue;
blocks[mask].assign(block_size, vector<int>(block_size));
for (int l = 0; l < block_size; l++) {
blocks[mask][l][l] = l;
for (int r = l + 1; r < block_size; r++) {
blocks[mask][l][r] = blocks[mask][l][r - 1];
if (b * block_size + r < m)
blocks[mask][l][r] = min_by_h(b * block_size + blocks[mask][l][r],
b * block_size + r) - b * block_size;
}
}
}
}
int lca_in_block(int b, int l, int r) {
return blocks[block_mask[b]][l][r] + b * block_size;
}
int lca(int v, int u) {
int l = first_visit[v];
int r = first_visit[u];
if (l > r)
swap(l, r);
int bl = l / block_size;
int br = r / block_size;
if (bl == br)
return euler_tour[lca_in_block(bl, l % block_size, r % block_size)];
int ans1 = lca_in_block(bl, l % block_size, block_size - 1);
int ans2 = lca_in_block(br, 0, r % block_size);
int ans = min_by_h(ans1, ans2);
if (bl + 1 < br) {
int l = log_2[br - bl - 1];
int ans3 = st[bl+1][l];
int ans4 = st[br - (1 << l)][l];
ans = min_by_h(ans, min_by_h(ans3, ans4));
}
return euler_tour[ans];
}
import sys
class LCA:
def __init__(self, adj, root=0):
self.n = len(adj)
self.adj = adj
self.first_visit = [-1] * self.n
self.height = [0] * self.n
self.euler_tour = []
# Глибина рекурсії DFS може сягати O(N), тому піднімаємо ліміт.
sys.setrecursionlimit(max(10**6, self.n * 2 + 10))
self.precompute_lca(root)
def dfs(self, v, p, h):
self.first_visit[v] = len(self.euler_tour)
self.euler_tour.append(v)
self.height[v] = h
for u in self.adj[v]:
if u == p:
continue
self.dfs(u, v, h + 1)
self.euler_tour.append(v)
def min_by_h(self, i, j):
# повертаємо індекс елемента ейлерового обходу з меншою висотою
return i if self.height[self.euler_tour[i]] < self.height[self.euler_tour[j]] else j
def precompute_lca(self, root):
# отримуємо ейлерів обхід та індекси перших входжень
self.dfs(root, -1, 0)
# заздалегідь обчислюємо всі значення логарифма
m = len(self.euler_tour)
self.log_2 = [-1] * (m + 1)
for i in range(1, m + 1):
self.log_2[i] = self.log_2[i // 2] + 1
self.block_size = max(1, self.log_2[m] // 2)
self.block_cnt = (m + self.block_size - 1) // self.block_size
# заздалегідь обчислюємо мінімум кожного блоку та будуємо розріджену таблицю
self.st = [[0] * (self.log_2[self.block_cnt] + 1) for _ in range(self.block_cnt)]
j, b = 0, 0
for i in range(m):
if j == self.block_size:
j = 0
b += 1
if j == 0 or self.min_by_h(i, self.st[b][0]) == i:
self.st[b][0] = i
j += 1
for l in range(1, self.log_2[self.block_cnt] + 1):
for i in range(self.block_cnt):
ni = i + (1 << (l - 1))
if ni >= self.block_cnt:
self.st[i][l] = self.st[i][l - 1]
else:
self.st[i][l] = self.min_by_h(self.st[i][l - 1], self.st[ni][l - 1])
# заздалегідь обчислюємо маску для кожного блоку
self.block_mask = [0] * self.block_cnt
j, b = 0, 0
for i in range(m):
if j == self.block_size:
j = 0
b += 1
if j > 0 and (i >= m or self.min_by_h(i - 1, i) == i - 1):
self.block_mask[b] += 1 << (j - 1)
j += 1
# заздалегідь обчислюємо RMQ для кожного унікального блоку
possibilities = 1 << (self.block_size - 1)
self.blocks = [None] * possibilities
for b in range(self.block_cnt):
mask = self.block_mask[b]
if self.blocks[mask] is not None:
continue
block = [[0] * self.block_size for _ in range(self.block_size)]
for l in range(self.block_size):
block[l][l] = l
for r in range(l + 1, self.block_size):
block[l][r] = block[l][r - 1]
if b * self.block_size + r < m:
block[l][r] = self.min_by_h(
b * self.block_size + block[l][r],
b * self.block_size + r) - b * self.block_size
self.blocks[mask] = block
def lca_in_block(self, b, l, r):
return self.blocks[self.block_mask[b]][l][r] + b * self.block_size
def lca(self, v, u):
l = self.first_visit[v]
r = self.first_visit[u]
if l > r:
l, r = r, l
bl = l // self.block_size
br = r // self.block_size
if bl == br:
return self.euler_tour[self.lca_in_block(bl, l % self.block_size, r % self.block_size)]
ans1 = self.lca_in_block(bl, l % self.block_size, self.block_size - 1)
ans2 = self.lca_in_block(br, 0, r % self.block_size)
ans = self.min_by_h(ans1, ans2)
if bl + 1 < br:
lg = self.log_2[br - bl - 1]
ans3 = self.st[bl + 1][lg]
ans4 = self.st[br - (1 << lg)][lg]
ans = self.min_by_h(ans, self.min_by_h(ans3, ans4))
return self.euler_tour[ans]
class LCA {
n: number;
adj: number[][];
firstVisit: number[];
height: number[];
eulerTour: number[];
log2: number[];
st: number[][];
blocks: (number[][] | null)[];
blockMask: number[];
blockSize: number;
blockCnt: number;
constructor(adj: number[][], root = 0) {
this.n = adj.length;
this.adj = adj;
this.firstVisit = new Array(this.n).fill(-1);
this.height = new Array(this.n).fill(0);
this.eulerTour = [];
this.precomputeLca(root);
}
dfs(v: number, p: number, h: number): void {
this.firstVisit[v] = this.eulerTour.length;
this.eulerTour.push(v);
this.height[v] = h;
for (const u of this.adj[v]) {
if (u === p) continue;
this.dfs(u, v, h + 1);
this.eulerTour.push(v);
}
}
// повертаємо індекс елемента ейлерового обходу з меншою висотою
minByH(i: number, j: number): number {
return this.height[this.eulerTour[i]] < this.height[this.eulerTour[j]] ? i : j;
}
precomputeLca(root: number): void {
// отримуємо ейлерів обхід та індекси перших входжень
this.dfs(root, -1, 0);
// заздалегідь обчислюємо всі значення логарифма
const m = this.eulerTour.length;
this.log2 = new Array(m + 1).fill(-1);
for (let i = 1; i <= m; i++) this.log2[i] = this.log2[i >> 1] + 1;
this.blockSize = Math.max(1, this.log2[m] >> 1);
this.blockCnt = Math.floor((m + this.blockSize - 1) / this.blockSize);
// заздалегідь обчислюємо мінімум кожного блоку та будуємо розріджену таблицю
this.st = Array.from({ length: this.blockCnt }, () =>
new Array(this.log2[this.blockCnt] + 1).fill(0)
);
for (let i = 0, j = 0, b = 0; i < m; i++, j++) {
if (j === this.blockSize) {
j = 0;
b++;
}
if (j === 0 || this.minByH(i, this.st[b][0]) === i) this.st[b][0] = i;
}
for (let l = 1; l <= this.log2[this.blockCnt]; l++) {
for (let i = 0; i < this.blockCnt; i++) {
const ni = i + (1 << (l - 1));
if (ni >= this.blockCnt) this.st[i][l] = this.st[i][l - 1];
else this.st[i][l] = this.minByH(this.st[i][l - 1], this.st[ni][l - 1]);
}
}
// заздалегідь обчислюємо маску для кожного блоку
this.blockMask = new Array(this.blockCnt).fill(0);
for (let i = 0, j = 0, b = 0; i < m; i++, j++) {
if (j === this.blockSize) {
j = 0;
b++;
}
if (j > 0 && (i >= m || this.minByH(i - 1, i) === i - 1))
this.blockMask[b] += 1 << (j - 1);
}
// заздалегідь обчислюємо RMQ для кожного унікального блоку
const possibilities = 1 << (this.blockSize - 1);
this.blocks = new Array(possibilities).fill(null);
for (let b = 0; b < this.blockCnt; b++) {
const mask = this.blockMask[b];
if (this.blocks[mask] !== null) continue;
const block: number[][] = Array.from({ length: this.blockSize }, () =>
new Array(this.blockSize).fill(0)
);
for (let l = 0; l < this.blockSize; l++) {
block[l][l] = l;
for (let r = l + 1; r < this.blockSize; r++) {
block[l][r] = block[l][r - 1];
if (b * this.blockSize + r < m)
block[l][r] =
this.minByH(b * this.blockSize + block[l][r], b * this.blockSize + r) -
b * this.blockSize;
}
}
this.blocks[mask] = block;
}
}
lcaInBlock(b: number, l: number, r: number): number {
return this.blocks[this.blockMask[b]]![l][r] + b * this.blockSize;
}
lca(v: number, u: number): number {
let l = this.firstVisit[v];
let r = this.firstVisit[u];
if (l > r) [l, r] = [r, l];
const bl = Math.floor(l / this.blockSize);
const br = Math.floor(r / this.blockSize);
if (bl === br)
return this.eulerTour[
this.lcaInBlock(bl, l % this.blockSize, r % this.blockSize)
];
const ans1 = this.lcaInBlock(bl, l % this.blockSize, this.blockSize - 1);
const ans2 = this.lcaInBlock(br, 0, r % this.blockSize);
let ans = this.minByH(ans1, ans2);
if (bl + 1 < br) {
const lg = this.log2[br - bl - 1];
const ans3 = this.st[bl + 1][lg];
const ans4 = this.st[br - (1 << lg)][lg];
ans = this.minByH(ans, this.minByH(ans3, ans4));
}
return this.eulerTour[ans];
}
}
type LCA struct {
n int
adj [][]int
firstVisit []int
eulerTour []int
height []int
log2 []int
st [][]int
blocks [][][]int
blockMask []int
blockSize int
blockCnt int
}
func NewLCA(adj [][]int, root int) *LCA {
l := &LCA{n: len(adj), adj: adj}
l.firstVisit = make([]int, l.n)
for i := range l.firstVisit {
l.firstVisit[i] = -1
}
l.height = make([]int, l.n)
l.eulerTour = make([]int, 0, 2*l.n)
l.precomputeLca(root)
return l
}
func (l *LCA) dfs(v, p, h int) {
l.firstVisit[v] = len(l.eulerTour)
l.eulerTour = append(l.eulerTour, v)
l.height[v] = h
for _, u := range l.adj[v] {
if u == p {
continue
}
l.dfs(u, v, h+1)
l.eulerTour = append(l.eulerTour, v)
}
}
// повертаємо індекс елемента ейлерового обходу з меншою висотою
func (l *LCA) minByH(i, j int) int {
if l.height[l.eulerTour[i]] < l.height[l.eulerTour[j]] {
return i
}
return j
}
func (l *LCA) precomputeLca(root int) {
// отримуємо ейлерів обхід та індекси перших входжень
l.dfs(root, -1, 0)
// заздалегідь обчислюємо всі значення логарифма
m := len(l.eulerTour)
l.log2 = make([]int, m+1)
l.log2[0] = -1
for i := 1; i <= m; i++ {
l.log2[i] = l.log2[i/2] + 1
}
l.blockSize = l.log2[m] / 2
if l.blockSize < 1 {
l.blockSize = 1
}
l.blockCnt = (m + l.blockSize - 1) / l.blockSize
// заздалегідь обчислюємо мінімум кожного блоку та будуємо розріджену таблицю
l.st = make([][]int, l.blockCnt)
for i := range l.st {
l.st[i] = make([]int, l.log2[l.blockCnt]+1)
}
for i, j, b := 0, 0, 0; i < m; i, j = i+1, j+1 {
if j == l.blockSize {
j, b = 0, b+1
}
if j == 0 || l.minByH(i, l.st[b][0]) == i {
l.st[b][0] = i
}
}
for lvl := 1; lvl <= l.log2[l.blockCnt]; lvl++ {
for i := 0; i < l.blockCnt; i++ {
ni := i + (1 << (lvl - 1))
if ni >= l.blockCnt {
l.st[i][lvl] = l.st[i][lvl-1]
} else {
l.st[i][lvl] = l.minByH(l.st[i][lvl-1], l.st[ni][lvl-1])
}
}
}
// заздалегідь обчислюємо маску для кожного блоку
l.blockMask = make([]int, l.blockCnt)
for i, j, b := 0, 0, 0; i < m; i, j = i+1, j+1 {
if j == l.blockSize {
j, b = 0, b+1
}
if j > 0 && (i >= m || l.minByH(i-1, i) == i-1) {
l.blockMask[b] += 1 << (j - 1)
}
}
// заздалегідь обчислюємо RMQ для кожного унікального блоку
possibilities := 1 << (l.blockSize - 1)
l.blocks = make([][][]int, possibilities)
for b := 0; b < l.blockCnt; b++ {
mask := l.blockMask[b]
if l.blocks[mask] != nil {
continue
}
block := make([][]int, l.blockSize)
for i := range block {
block[i] = make([]int, l.blockSize)
}
for left := 0; left < l.blockSize; left++ {
block[left][left] = left
for r := left + 1; r < l.blockSize; r++ {
block[left][r] = block[left][r-1]
if b*l.blockSize+r < m {
block[left][r] = l.minByH(b*l.blockSize+block[left][r],
b*l.blockSize+r) - b*l.blockSize
}
}
}
l.blocks[mask] = block
}
}
func (l *LCA) lcaInBlock(b, left, r int) int {
return l.blocks[l.blockMask[b]][left][r] + b*l.blockSize
}
func (l *LCA) lca(v, u int) int {
left := l.firstVisit[v]
r := l.firstVisit[u]
if left > r {
left, r = r, left
}
bl := left / l.blockSize
br := r / l.blockSize
if bl == br {
return l.eulerTour[l.lcaInBlock(bl, left%l.blockSize, r%l.blockSize)]
}
ans1 := l.lcaInBlock(bl, left%l.blockSize, l.blockSize-1)
ans2 := l.lcaInBlock(br, 0, r%l.blockSize)
ans := l.minByH(ans1, ans2)
if bl+1 < br {
lg := l.log2[br-bl-1]
ans3 := l.st[bl+1][lg]
ans4 := l.st[br-(1<<lg)][lg]
ans = l.minByH(ans, l.minByH(ans3, ans4))
}
return l.eulerTour[ans]
}