Важко-легка декомпозиція
Важко-легка декомпозиція (HLD) — це доволі загальна техніка, яка дозволяє ефективно розв'язувати багато задач, що зводяться до запитів на дереві.
- Потрібні запити (сума/мінімум/максимум) і оновлення на шляху між двома вершинами дерева, а не лише в піддереві?
- Запити змінюють значення вершин/ребер (онлайн з оновленнями), тож статичних технік недостатньо? (якщо потрібен лише найнижчий спільний предок без агрегатів → простіший LCA через двійкові підйоми)
- Дерево статичне за структурою, щоб один раз розбити його на важкі шляхи й покласти зверху дерево відрізків?
Опис
Нехай задано дерево із вершин з довільним коренем.
Суть цієї декомпозиції дерева полягає в тому, щоб розбити дерево на кілька шляхів так, щоб з будь-якої вершини можна було дістатися до кореня, пройшовши не більше ніж шляхів. До того ж жоден із цих шляхів не повинен перетинатися з іншим.
Зрозуміло, що якщо ми знайдемо таку декомпозицію для будь-якого дерева, вона дозволить нам звести певні окремі запити вигляду «обчислити щось на шляху від до » до кількох запитів вигляду «обчислити щось на відрізку -го шляху».
Алгоритм побудови
Для кожної вершини ми обчислюємо розмір її піддерева , тобто кількість вершин у піддереві вершини , включно з нею самою.
Далі розглянемо всі ребра, що ведуть до дітей вершини . Ми називаємо ребро важким, якщо воно веде до вершини такої, що:
Усі інші ребра позначаються як легкі.
Очевидно, що з однієї вершини вниз може виходити щонайбільше одне важке ребро, бо інакше вершина мала б принаймні двох дітей розміру , а тому розмір піддерева був би завеликим: , що призводить до суперечності.
Тепер ми розкладемо дерево на неперетинні шляхи. Розглянемо всі вершини, з яких не виходить вниз жодне важке ребро. З кожної такої вершини ми будемо підніматися вгору, доки не досягнемо кореня дерева або не пройдемо легким ребром. У результаті ми отримаємо кілька шляхів, які складаються з нуля або більше важких ребер плюс одне легке ребро. Виняток становить шлях, що закінчується в корені — він не матиме легкого ребра. Назвемо їх важкими шляхами — це і є шукані шляхи важко-легкої декомпозиції.
Доведення коректності
Спершу зауважимо, що важкі шляхи, отримані алгоритмом, будуть неперетинними. Справді, якби два такі шляхи мали спільне ребро, це означало б, що з однієї вершини виходять два важкі ребра, що неможливо.
По-друге, ми покажемо, що, спускаючись від кореня дерева до довільної вершини, ми змінимо не більше ніж важких шляхів по дорозі. Спуск легким ребром зменшує розмір поточного піддерева вдвічі або більше:
Отже, ми можемо пройти щонайбільше легких ребер, перш ніж розмір піддерева зменшиться до одиниці.
Оскільки переходити з одного важкого шляху на інший можна лише через легке ребро (кожен важкий шлях, окрім того, що починається в корені, має одне легке ребро), ми не можемо змінити важкі шляхи більш ніж разів на шляху від кореня до будь-якої вершини, що й потрібно було довести.
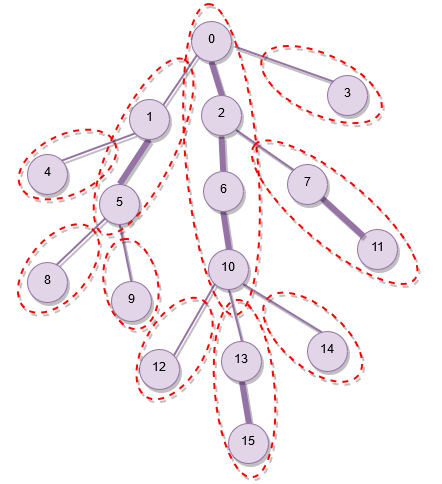
На наступному зображенні проілюстровано декомпозицію зразкового дерева. Важкі ребра товщі за легкі. Важкі шляхи позначені пунктирними межами.
Приклади задач
При розв'язуванні задач іноді зручніше розглядати важко-легку декомпозицію як набір шляхів, що не перетинаються по вершинах (а не по ребрах). Для цього достатньо виключити останнє ребро з кожного важкого шляху, якщо воно є легким ребром — тоді жодна властивість не порушується, але тепер кожна вершина належить рівно одному важкому шляху.
Нижче ми розглянемо кілька типових задач, які можна розв'язати за допомогою важко-легкої декомпозиції.
Окремо варто звернути увагу на задачу про суму чисел на шляху, оскільки це приклад задачі, яку можна розв'язати простішими методами.
Максимальне значення на шляху між двома вершинами
Дано дерево, кожній вершині якого присвоєно значення. Є запити вигляду , де та — дві вершини дерева, і потрібно знайти максимальне значення на шляху між вершинами та .
Наперед ми будуємо важко-легку декомпозицію дерева. Над кожним важким шляхом ми побудуємо дерево відрізків, яке дозволить нам шукати вершину з максимальним присвоєним значенням на заданому відрізку заданого важкого шляху за . Хоча кількість важких шляхів у важко-легкій декомпозиції може сягати , сумарний розмір усіх шляхів обмежений , тому сумарний розмір дерев відрізків також буде лінійним.
Щоб відповісти на запит , ми знаходимо найнижчий спільний предок вершин та як будь-яким зручним методом. Тепер задача звелася до двох запитів та , для кожного з яких ми можемо зробити так: знайти важкий шлях, на якому лежить нижня вершина, зробити запит на цьому шляху, перейти до вершини цього шляху, знову визначити, на якому важкому шляху ми перебуваємо, і зробити запит на ньому, і так далі, доки не дістанемося шляху, що містить .
Слід бути обережним з випадком, коли, наприклад, та лежать на одному важкому шляху — тоді запит максимуму на цьому шляху слід робити не на якомусь префіксі, а на внутрішній ділянці між та .
Відповідь на підзапити та кожна потребує проходження важких шляхів, і для кожного шляху робиться запит максимуму на якійсь ділянці шляху, що знову ж таки потребує операцій у дереві відрізків. Отже, один запит займає часу.
Якщо додатково обчислити й зберегти максимуми всіх префіксів для кожного важкого шляху, то отримаємо розв'язок за , оскільки всі запити максимуму будуть на префіксах, за винятком щонайбільше одного разу, коли ми досягаємо предка .
Сума чисел на шляху між двома вершинами
Дано дерево, кожній вершині якого присвоєно значення. Є запити вигляду , де та — дві вершини дерева, і потрібно знайти суму значень на шляху між вершинами та . Можливий варіант цієї задачі, де додатково є операції оновлення, які змінюють число, присвоєне одній чи кільком вершинам.
Цю задачу можна розв'язати аналогічно до попередньої задачі про максимуми за допомогою важко-легкої декомпозиції, будуючи дерева відрізків на важких шляхах. Замість цього можна використати префіксні суми, якщо немає оновлень. Однак цю задачу теж можна розв'язати простішими методами.
Якщо оновлень немає, то можна знайти суму на шляху між двома вершинами паралельно з пошуком LCA двох вершин за допомогою бінарного підйому — для цього разом із -ми предками кожної вершини під час попередньої обробки також необхідно зберігати суму на шляхах до тих предків.
Існує принципово інший підхід до цієї задачі — розглянути ейлерів обхід дерева й побудувати на ньому дерево відрізків. Цей алгоритм розглянуто в статті про схожу задачу. Знову ж таки, якщо оновлень немає, достатньо зберігати префіксні суми, а дерево відрізків не потрібне.
Обидва ці методи дають відносно прості розв'язки, що займають на один запит.
Перефарбовування ребер шляху між двома вершинами
Дано дерево, кожне ребро якого спершу пофарбоване в білий колір. Є оновлення вигляду , де та — дві вершини, а — колір, які наказують перефарбувати всі ребра на шляху від до у колір . Після всіх перефарбовувань потрібно повідомити, скільки ребер кожного кольору вийшло.
Аналогічно до наведених вище задач, розв'язок полягає в тому, щоб просто застосувати важко-легку декомпозицію й зробити дерево відрізків над кожним важким шляхом.
Кожне перефарбовування на шляху перетвориться на два оновлення та , де — найнижчий спільний предок вершин та .
на шлях для шляхів дає складність на одне оновлення.
Реалізація
Деякі частини розглянутого вище підходу можна змінити, щоб полегшити реалізацію, не втрачаючи ефективності.
- Означення важкого ребра можна змінити на ребро, що веде до дитини з найбільшим піддеревом, з довільним розв'язанням нічиїх. Це може призвести до того, що деякі легкі ребра стануть важкими, а отже, деякі важкі шляхи об'єднаються в один шлях, але всі важкі шляхи залишаться неперетинними. Також усе ще гарантовано, що спуск легким ребром зменшує розмір піддерева вдвічі або більше.
- Замість того щоб будувати дерево відрізків над кожним важким шляхом, можна використати одне дерево відрізків з неперетинними відрізками, виділеними кожному важкому шляху.
- Уже згадувалося, що відповідь на запити потребує обчислення LCA. Хоча LCA можна обчислювати окремо, обчислення LCA також можна інтегрувати в процес відповіді на запити.
Щоб виконати важко-легку декомпозицію:
- C++
- Python
- TypeScript
- Go
vector<int> parent, depth, heavy, head, pos;
int cur_pos;
int dfs(int v, vector<vector<int>> const& adj) {
int size = 1;
int max_c_size = 0;
for (int c : adj[v]) {
if (c != parent[v]) {
parent[c] = v, depth[c] = depth[v] + 1;
int c_size = dfs(c, adj);
size += c_size;
if (c_size > max_c_size)
max_c_size = c_size, heavy[v] = c;
}
}
return size;
}
void decompose(int v, int h, vector<vector<int>> const& adj) {
head[v] = h, pos[v] = cur_pos++;
if (heavy[v] != -1)
decompose(heavy[v], h, adj);
for (int c : adj[v]) {
if (c != parent[v] && c != heavy[v])
decompose(c, c, adj);
}
}
void init(vector<vector<int>> const& adj) {
int n = adj.size();
parent = vector<int>(n);
depth = vector<int>(n);
heavy = vector<int>(n, -1);
head = vector<int>(n);
pos = vector<int>(n);
cur_pos = 0;
dfs(0, adj);
decompose(0, 0, adj);
}
import sys
# DFS і decompose рекурсивні; для глибоких (вироджених) дерев
# збільшуємо ліміт рекурсії, інакше можливий RecursionError.
sys.setrecursionlimit(1 << 20)
parent: list[int] = []
depth: list[int] = []
heavy: list[int] = []
head: list[int] = []
pos: list[int] = []
cur_pos = 0
def dfs(v: int, adj: list[list[int]]) -> int:
size = 1
max_c_size = 0
for c in adj[v]:
if c != parent[v]:
parent[c] = v
depth[c] = depth[v] + 1
c_size = dfs(c, adj)
size += c_size
if c_size > max_c_size:
max_c_size, heavy[v] = c_size, c
return size
def decompose(v: int, h: int, adj: list[list[int]]) -> None:
global cur_pos
head[v] = h
pos[v] = cur_pos
cur_pos += 1
if heavy[v] != -1:
decompose(heavy[v], h, adj)
for c in adj[v]:
if c != parent[v] and c != heavy[v]:
decompose(c, c, adj)
def init(adj: list[list[int]]) -> None:
global parent, depth, heavy, head, pos, cur_pos
n = len(adj)
parent = [0] * n
depth = [0] * n
heavy = [-1] * n
head = [0] * n
pos = [0] * n
cur_pos = 0
dfs(0, adj)
decompose(0, 0, adj)
let parent: number[] = [];
let depth: number[] = [];
let heavy: number[] = [];
let head: number[] = [];
let pos: number[] = [];
let curPos = 0;
function dfs(v: number, adj: number[][]): number {
let size = 1;
let maxCSize = 0;
for (const c of adj[v]) {
if (c !== parent[v]) {
parent[c] = v;
depth[c] = depth[v] + 1;
const cSize = dfs(c, adj);
size += cSize;
if (cSize > maxCSize) {
maxCSize = cSize;
heavy[v] = c;
}
}
}
return size;
}
function decompose(v: number, h: number, adj: number[][]): void {
head[v] = h;
pos[v] = curPos++;
if (heavy[v] !== -1) decompose(heavy[v], h, adj);
for (const c of adj[v]) {
if (c !== parent[v] && c !== heavy[v]) decompose(c, c, adj);
}
}
function init(adj: number[][]): void {
const n = adj.length;
parent = new Array(n).fill(0);
depth = new Array(n).fill(0);
heavy = new Array(n).fill(-1);
head = new Array(n).fill(0);
pos = new Array(n).fill(0);
curPos = 0;
dfs(0, adj);
decompose(0, 0, adj);
}
var (
parent []int
depth []int
heavy []int
head []int
pos []int
curPos int
)
func dfs(v int, adj [][]int) int {
size := 1
maxCSize := 0
for _, c := range adj[v] {
if c != parent[v] {
parent[c] = v
depth[c] = depth[v] + 1
cSize := dfs(c, adj)
size += cSize
if cSize > maxCSize {
maxCSize, heavy[v] = cSize, c
}
}
}
return size
}
func decompose(v, h int, adj [][]int) {
head[v] = h
pos[v] = curPos
curPos++
if heavy[v] != -1 {
decompose(heavy[v], h, adj)
}
for _, c := range adj[v] {
if c != parent[v] && c != heavy[v] {
decompose(c, c, adj)
}
}
}
func initHLD(adj [][]int) {
n := len(adj)
parent = make([]int, n)
depth = make([]int, n)
heavy = make([]int, n)
for i := range heavy {
heavy[i] = -1
}
head = make([]int, n)
pos = make([]int, n)
curPos = 0
dfs(0, adj)
decompose(0, 0, adj)
}
У функцію init необхідно передати список суміжності дерева, і декомпозиція виконується, вважаючи вершину 0 коренем.
Функція dfs використовується для обчислення heavy[v] — дитини на іншому кінці важкого ребра з v — для кожної вершини v. Крім того, dfs також зберігає батька та глибину кожної вершини, що стане в нагоді пізніше під час запитів.
Функція decompose присвоює кожній вершині v значення head[v] та pos[v], які є відповідно головою важкого шляху, до якого належить v, та позицією v в єдиному дереві відрізків, що покриває всі вершини.
Щоб відповідати на запити на шляхах, наприклад на розглянутий запит максимуму, ми можемо зробити щось на кшталт цього:
- C++
- Python
- TypeScript
- Go
int query(int a, int b) {
int res = 0;
for (; head[a] != head[b]; b = parent[head[b]]) {
if (depth[head[a]] > depth[head[b]])
swap(a, b);
int cur_heavy_path_max = segment_tree_query(pos[head[b]], pos[b]);
res = max(res, cur_heavy_path_max);
}
if (depth[a] > depth[b])
swap(a, b);
int last_heavy_path_max = segment_tree_query(pos[a], pos[b]);
res = max(res, last_heavy_path_max);
return res;
}
def query(a: int, b: int) -> int:
res = 0
while head[a] != head[b]:
if depth[head[a]] > depth[head[b]]:
a, b = b, a
cur_heavy_path_max = segment_tree_query(pos[head[b]], pos[b])
res = max(res, cur_heavy_path_max)
b = parent[head[b]]
if depth[a] > depth[b]:
a, b = b, a
last_heavy_path_max = segment_tree_query(pos[a], pos[b])
res = max(res, last_heavy_path_max)
return res
function query(a: number, b: number): number {
let res = 0;
for (; head[a] !== head[b]; b = parent[head[b]]) {
if (depth[head[a]] > depth[head[b]]) [a, b] = [b, a];
const curHeavyPathMax = segmentTreeQuery(pos[head[b]], pos[b]);
res = Math.max(res, curHeavyPathMax);
}
if (depth[a] > depth[b]) [a, b] = [b, a];
const lastHeavyPathMax = segmentTreeQuery(pos[a], pos[b]);
res = Math.max(res, lastHeavyPathMax);
return res;
}
func query(a, b int) int {
res := 0
for ; head[a] != head[b]; b = parent[head[b]] {
if depth[head[a]] > depth[head[b]] {
a, b = b, a
}
curHeavyPathMax := segmentTreeQuery(pos[head[b]], pos[b])
res = max(res, curHeavyPathMax)
}
if depth[a] > depth[b] {
a, b = b, a
}
lastHeavyPathMax := segmentTreeQuery(pos[a], pos[b])
res = max(res, lastHeavyPathMax)
return res
}
Задачі для практики
- SPOJ - QTREE - Query on a tree
- CSES - Path Queries II
- Codeforces - Subway Lines
- Codeforces - Tree Queries
- Codeforces - Tree or not Tree
- Codeforces - The Tree
- Balkan OI 2018 - Min-max tree