Пошук найближчої пари точок
Постановка задачі
Задано точок на площині. Кожна точка задана своїми координатами . Потрібно знайти серед них дві такі точки, щоб відстань між ними була мінімальною:
Беремо звичайні евклідові відстані:
Тривіальний алгоритм — перебір усіх пар і обчислення відстані для кожної — працює за .
Нижче описано алгоритм, що працює за час . Цей алгоритм запропонували Shamos і Hoey у 1975 році. (Джерело: Ch. 5 Notes of Algorithm Design by Kleinberg & Tardos, також див. тут) Preparata і Shamos також показали, що цей алгоритм є оптимальним у моделі дерева розв'язків.
- Вам потрібна саме найближча пара серед точок (одна мінімальна відстань), а не всі попарні відстані?
- Відстань вимірюється евклідово? (якщо це метрика → див. трюки в Мангеттенська відстань)
- Тривіальний перебір усіх пар за занадто повільний для вашого , тож потрібен підхід «розділяй і володарюй» за ?
Алгоритм
Будуємо алгоритм за загальною схемою алгоритмів «розділяй і володарюй»: алгоритм оформлений як рекурсивна функція, якій ми передаємо множину точок; ця рекурсивна функція розбиває цю множину навпіл, рекурсивно викликає себе на кожній половині, а потім виконує деякі операції, щоб об'єднати відповіді. Операція об'єднання полягає у виявленні випадків, коли одна точка оптимального розв'язку потрапила в одну половину, а інша — у другу (у цьому випадку рекурсивні виклики з кожної з половин не зможуть виявити цю пару окремо). Основна складність, як завжди у випадку алгоритмів «розділяй і володарюй», полягає в ефективній реалізації етапу злиття. Якщо рекурсивній функції передається множина з точок, то етап злиття має працювати не довше ніж , тоді асимптотику всього алгоритму буде знайдено з рівняння:
Розв'язком цього рівняння, як відомо, є
Отже, переходимо до побудови алгоритму. Щоб у майбутньому дійти до ефективної реалізації етапу злиття, ми розділимо множину точок на дві підмножини за їхніми -координатами: фактично ми проводимо деяку вертикальну пряму, що ділить множину точок на дві підмножини приблизно однакового розміру. Таке розбиття зручно зробити так: сортуємо точки стандартним чином як пари чисел, тобто:
Потім беремо середню точку після сортування , і всі точки до неї та саму відносимо до першої половини, а всі точки після неї — до другої половини:
Тепер, рекурсивно викликаючись на кожній з множин і , ми знайдемо відповіді і для кожної з половин. І візьмемо кращу з них: .
Тепер нам потрібно виконати етап злиття, тобто ми намагаємося знайти такі пари точок, відстань між якими менша за і одна точка лежить в , а інша — в . Очевидно, що достатньо розглянути лише ті точки, які відокремлені від вертикальної прямої на відстань, меншу за , тобто множина точок, що розглядаються на цьому етапі, дорівнює:
Для кожної точки з множини ми намагаємося знайти точки, ближчі до неї, ніж . Наприклад, достатньо розглянути лише ті точки, -координата яких відрізняється не більш ніж на . Більше того, немає сенсу розглядати ті точки, -координата яких більша за -координату поточної точки. Таким чином, для кожної точки ми визначаємо множину розглядуваних точок так:
Якщо ми відсортуємо точки множини за -координатою, то знайти буде дуже легко: це кілька точок поспіль перед точкою .
Отже, у нових позначеннях етап злиття виглядає так: будуємо множину , сортуємо точки в ній за -координатою, потім для кожної точки розглядаємо всі точки , і для кожної пари обчислюємо відстань і порівнюємо з поточною найкращою відстанню.
На перший погляд це все ще неоптимальний алгоритм: здається, що розміри множин будуть порядку , і потрібна асимптотика не вийде. Однак, на диво, можна довести, що розмір кожної з множин є величиною , тобто не перевищує деякої малої сталої незалежно від самих точок. Доведення цього факту наведено в наступному розділі.
Нарешті, звернемо увагу на сортування, які містить наведений вище алгоритм: по-перше, сортування за парами , а по-друге, сортування елементів множини за . Насправді обидва ці сортування всередині рекурсивної функції можна усунути (інакше ми не досягли б оцінки для етапу злиття, і загальна асимптотика алгоритму була б ). Позбутися першого сортування легко — достатньо виконати це сортування перед початком рекурсії: адже самі елементи всередині рекурсії не змінюються, тому немає потреби сортувати знову. З другим сортуванням трохи складніше, виконати його заздалегідь не вийде. Але, згадавши сортування злиттям, яке теж працює за принципом «розділяй і володарюй», ми можемо просто вбудувати це сортування в нашу рекурсію. Нехай рекурсія, отримуючи деяку множину точок (як ми пам'ятаємо, упорядковану за парами ), повертає ту саму множину, але відсортовану за -координатою. Для цього достатньо злити (за ) два результати, повернені рекурсивними викликами. Це дасть множину, відсортовану за -координатою.
Оцінка асимптотики
Щоб показати, що наведений вище алгоритм насправді виконується за , нам потрібно довести такий факт: .
Отже, розглянемо деяку точку ; нагадаємо, що множина — це множина точок, -координата яких лежить у відрізку , і, до того ж, за координатою сама точка та всі точки множини лежать у смузі шириною . Інакше кажучи, розглядувані нами точки та лежать у прямокутнику розміром .
Наше завдання — оцінити максимальну кількість точок, які можуть лежати в цьому прямокутнику ; так ми оцінимо максимальний розмір множини . При цьому, оцінюючи, ми не повинні забувати, що можуть бути повторювані точки.
Згадаймо, що було отримано з результатів двох рекурсивних викликів — на множинах та , причому містить точки ліворуч від прямої розбиття та частково на ній, містить решту точок прямої розбиття та точки праворуч від неї. Для будь-якої пари точок з , як і з , відстань не може бути меншою за — інакше це означало б некоректну роботу рекурсивної функції.
Щоб оцінити максимальну кількість точок у прямокутнику , поділимо його на два квадрати , перший квадрат включає всі точки , а другий містить усі інші, тобто . З наведених вище міркувань випливає, що в кожному з цих квадратів відстань між будь-якими двома точками щонайменше .
Покажемо, що в кожному квадраті є не більше чотирьох точок. Наприклад, це можна зробити так: поділимо квадрат на підквадрати зі сторонами . Тоді в кожному з цих підквадратів не може бути більше однієї точки (оскільки навіть діагональ дорівнює , що менше за ). Отже, у всьому квадраті не може бути більше ніж точки.
Отже, ми довели, що в прямокутнику не може бути більше ніж точок, і, отже, розмір множини не може перевищувати , що й вимагалося.
Реалізація
Уведемо структуру даних для зберігання точки (її координат і номера) та оператори порівняння, потрібні для двох типів сортування:
- C++
- Python
- TypeScript
- Go
struct pt {
int x, y, id;
};
struct cmp_x {
bool operator()(const pt & a, const pt & b) const {
return a.x < b.x || (a.x == b.x && a.y < b.y);
}
};
struct cmp_y {
bool operator()(const pt & a, const pt & b) const {
return a.y < b.y;
}
};
int n;
vector<pt> a;
from dataclasses import dataclass
# Точка: координати та її номер у вхідному масиві.
@dataclass
class Pt:
x: int
y: int
id: int
# Порівняння за парою (x, y) — для початкового сортування.
def cmp_x(p: Pt) -> tuple[int, int]:
return (p.x, p.y)
# Порівняння лише за y — для сортування під час злиття.
def cmp_y(p: Pt) -> int:
return p.y
n: int = 0
a: list[Pt] = []
// Точка: координати та її номер у вхідному масиві.
interface Pt {
x: number;
y: number;
id: number;
}
// Порівняння за парою (x, y) — для початкового сортування.
function cmpX(a: Pt, b: Pt): number {
return a.x - b.x || a.y - b.y;
}
// Порівняння лише за y — для сортування під час злиття.
function cmpY(a: Pt, b: Pt): number {
return a.y - b.y;
}
let n = 0;
let a: Pt[] = [];
// Точка: координати та її номер у вхідному масиві.
type Pt struct {
x, y, id int
}
// Порівняння за парою (x, y) — для початкового сортування.
func lessX(a, b Pt) bool {
return a.x < b.x || (a.x == b.x && a.y < b.y)
}
// Порівняння лише за y — для сортування під час злиття.
func lessY(a, b Pt) bool {
return a.y < b.y
}
var (
n int
a []Pt
)
Для зручної реалізації рекурсії вводимо допоміжну функцію upd_ans(), яка обчислюватиме відстань між двома точками й перевірятиме, чи вона краща за поточну відповідь:
- C++
- Python
- TypeScript
- Go
double mindist;
pair<int, int> best_pair;
void upd_ans(const pt & a, const pt & b) {
double dist = sqrt((a.x - b.x)*(a.x - b.x) + (a.y - b.y)*(a.y - b.y));
if (dist < mindist) {
mindist = dist;
best_pair = {a.id, b.id};
}
}
import math
mindist: float = 0.0
best_pair: tuple[int, int] = (-1, -1)
# Обчислюємо відстань між двома точками й оновлюємо відповідь, якщо вона краща.
def upd_ans(p: Pt, q: Pt) -> None:
global mindist, best_pair
dist = math.sqrt((p.x - q.x) ** 2 + (p.y - q.y) ** 2)
if dist < mindist:
mindist = dist
best_pair = (p.id, q.id)
let mindist = 0;
let bestPair: [number, number] = [-1, -1];
// Обчислюємо відстань між двома точками й оновлюємо відповідь, якщо вона краща.
function updAns(p: Pt, q: Pt): void {
const dist = Math.sqrt((p.x - q.x) ** 2 + (p.y - q.y) ** 2);
if (dist < mindist) {
mindist = dist;
bestPair = [p.id, q.id];
}
}
import "math"
var (
mindist float64
bestPair [2]int
)
// Обчислюємо відстань між двома точками й оновлюємо відповідь, якщо вона краща.
func updAns(p, q Pt) {
dx := float64(p.x - q.x)
dy := float64(p.y - q.y)
dist := math.Sqrt(dx*dx + dy*dy)
if dist < mindist {
mindist = dist
bestPair = [2]int{p.id, q.id}
}
}
Нарешті, реалізація самої рекурсії. Припускається, що перед її викликом масив уже відсортований за -координатою. У рекурсію ми передаємо лише два вказівники , які вказують, що вона має шукати відповідь для . Якщо відстань між і замала, рекурсію треба зупинити та виконати тривіальний алгоритм для пошуку найближчої пари, а потім відсортувати підмасив за -координатою.
Щоб злити дві множини точок, отримані з рекурсивних викликів, в одну (упорядковану за -координатою), ми використовуємо стандартну функцію STL і створюємо допоміжний буфер (один для всіх рекурсивних викликів). (Використовувати inplace_merge() недоцільно, бо вона загалом не працює за лінійний час.)
Нарешті, множина зберігається в тому самому масиві .
- C++
- Python
- TypeScript
- Go
vector<pt> t;
void rec(int l, int r) {
if (r - l <= 3) {
for (int i = l; i < r; ++i) {
for (int j = i + 1; j < r; ++j) {
upd_ans(a[i], a[j]);
}
}
sort(a.begin() + l, a.begin() + r, cmp_y());
return;
}
int m = (l + r) >> 1;
int midx = a[m].x;
rec(l, m);
rec(m, r);
merge(a.begin() + l, a.begin() + m, a.begin() + m, a.begin() + r, t.begin(), cmp_y());
copy(t.begin(), t.begin() + r - l, a.begin() + l);
int tsz = 0;
for (int i = l; i < r; ++i) {
if (abs(a[i].x - midx) < mindist) {
for (int j = tsz - 1; j >= 0 && a[i].y - t[j].y < mindist; --j)
upd_ans(a[i], t[j]);
t[tsz++] = a[i];
}
}
}
# Допоміжний буфер для злиття за y (один на всі виклики).
t: list[Pt] = []
def rec(l: int, r: int) -> None:
if r - l <= 3:
# Тривіальний переборний випадок для малого підмасиву.
for i in range(l, r):
for j in range(i + 1, r):
upd_ans(a[i], a[j])
# Сортуємо підмасив за y-координатою.
a[l:r] = sorted(a[l:r], key=cmp_y)
return
m = (l + r) >> 1
midx = a[m].x
rec(l, m)
rec(m, r)
# Зливаємо дві вже відсортовані за y половини в один відрізок.
merged = sorted(a[l:r], key=cmp_y) # стабільне злиття двох відсортованих частин
a[l:r] = merged
# Формуємо смугу B у буфері t і перебираємо кандидатів C(p_i).
tsz = 0
for i in range(l, r):
if abs(a[i].x - midx) < mindist:
j = tsz - 1
while j >= 0 and a[i].y - t[j].y < mindist:
upd_ans(a[i], t[j])
j -= 1
t[tsz] = a[i]
tsz += 1
// Допоміжний буфер для злиття за y (один на всі виклики).
let t: Pt[] = [];
function rec(l: number, r: number): void {
if (r - l <= 3) {
// Тривіальний переборний випадок для малого підмасиву.
for (let i = l; i < r; ++i)
for (let j = i + 1; j < r; ++j)
updAns(a[i], a[j]);
// Сортуємо підмасив за y-координатою.
const sub = a.slice(l, r).sort(cmpY);
for (let i = 0; i < sub.length; ++i) a[l + i] = sub[i];
return;
}
const m = (l + r) >> 1;
const midx = a[m].x;
rec(l, m);
rec(m, r);
// Зливаємо дві вже відсортовані за y половини в один відрізок.
const merged = a.slice(l, r).sort(cmpY);
for (let i = 0; i < merged.length; ++i) a[l + i] = merged[i];
// Формуємо смугу B у буфері t і перебираємо кандидатів C(p_i).
let tsz = 0;
for (let i = l; i < r; ++i) {
if (Math.abs(a[i].x - midx) < mindist) {
for (let j = tsz - 1; j >= 0 && a[i].y - t[j].y < mindist; --j)
updAns(a[i], t[j]);
t[tsz++] = a[i];
}
}
}
import "sort"
// Допоміжний буфер для злиття за y (один на всі виклики).
var t []Pt
func rec(l, r int) {
if r-l <= 3 {
// Тривіальний переборний випадок для малого підмасиву.
for i := l; i < r; i++ {
for j := i + 1; j < r; j++ {
updAns(a[i], a[j])
}
}
// Сортуємо підмасив за y-координатою.
sort.SliceStable(a[l:r], func(i, j int) bool { return lessY(a[l+i], a[l+j]) })
return
}
m := (l + r) >> 1
midx := a[m].x
rec(l, m)
rec(m, r)
// Зливаємо дві вже відсортовані за y половини в один відрізок.
sort.SliceStable(a[l:r], func(i, j int) bool { return lessY(a[l+i], a[l+j]) })
// Формуємо смугу B у буфері t і перебираємо кандидатів C(p_i).
tsz := 0
for i := l; i < r; i++ {
if float64(abs(a[i].x-midx)) < mindist {
for j := tsz - 1; j >= 0 && float64(a[i].y-t[j].y) < mindist; j-- {
updAns(a[i], t[j])
}
t[tsz] = a[i]
tsz++
}
}
}
func abs(x int) int {
if x < 0 {
return -x
}
return x
}
До речі, якщо всі координати цілі, то під час рекурсії можна не переходити до дробових значень і зберігати в квадрат мінімальної відстані.
У головній програмі рекурсію слід викликати так:
- C++
- Python
- TypeScript
- Go
t.resize(n);
sort(a.begin(), a.end(), cmp_x());
mindist = 1E20;
rec(0, n);
t = [None] * n # резервуємо буфер злиття
a.sort(key=cmp_x)
mindist = 1e20
rec(0, n)
t = new Array<Pt>(n); // резервуємо буфер злиття
a.sort(cmpX);
mindist = 1e20;
rec(0, n);
t = make([]Pt, n) // резервуємо буфер злиття
sort.SliceStable(a, func(i, j int) bool { return lessX(a[i], a[j]) })
mindist = 1e20
rec(0, n)
Рандомізовані алгоритми з лінійним часом
Рандомізований алгоритм з лінійним сподіваним часом
Альтернативний метод, спочатку запропонований Rabin у 1976 році, виникає з дуже простої ідеї евристично покращити час роботи: ми можемо поділити площину на сітку квадратів , тоді потрібно лише перевіряти відстані між точками одного блока або сусідніх блоків (хіба що всі квадрати від'єднані один від одного, але ми уникнемо цього за побудовою), оскільки будь-яка інша пара має більшу відстань, ніж дві точки в одному квадраті.
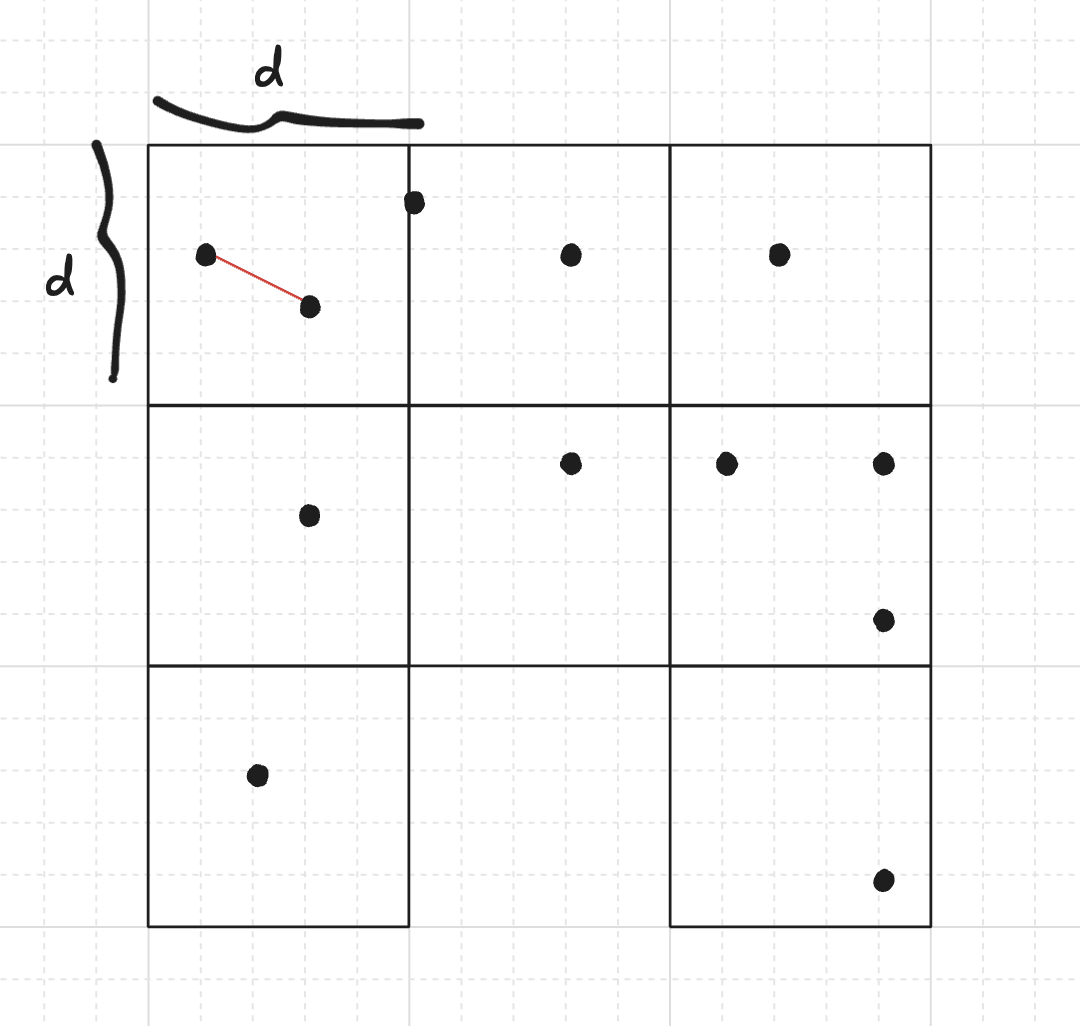
Ми розглядатимемо лише квадрати, що містять хоча б одну точку. Позначимо через кількість точок у кожному з решти квадратів. Припускаючи, що принаймні дві точки лежать в одному або в сусідніх квадратах і що немає дубльованих точок, часова складність дорівнює . Ми можемо шукати дубльовані точки за сподіваний лінійний час за допомогою хеш-таблиці, і в разі їх наявності відповіддю є ця пара.
Доведення
Для -го квадрата, що містить точок, кількість пар усередині дорівнює . Якщо -й квадрат сусідить із -м квадратом, то ми також виконуємо порівнянь відстаней. Зауважимо, що кожен квадрат має щонайбільше сусідніх квадратів, тому суму всіх порівнянь можна обмежити величиною .
Тепер нам потрібно визначитися з тим, як задати , щоб воно мінімізувало .
Вибір d
Нам потрібно, щоб було наближенням мінімальної відстані . Richard Lipton запропонував випадково взяти вибірку з відстаней і обрати як найменшу з цих відстаней як наближення для . Тепер ми доведемо, що сподіваний час роботи алгоритму є лінійним.
Доведення
Уявімо розташування точок у квадратах за певного вибору , скажімо . Розглянемо як випадкову величину, що виникає внаслідок нашої вибірки відстаней. Визначмо як оцінку вартості для конкретного розташування, коли ми обираємо . Тепер визначмо так, що . Яка ймовірність того, що такий вибір переживе вибірку з незалежних відстаней? Якщо хоча б одна пара серед обраних має відстань, меншу за , це розташування буде замінено на менше . Усередині квадрата приблизно пар дали б меншу відстань (уявімо чотири підквадрати в кожному квадраті; за принципом Діріхле, принаймні один підквадрат має точок), тож ми маємо приблизно пар, що дають менше підсумкове . Це, приблизно, . З іншого боку, є приблизно пар, які можуть бути обрані у вибірку. Маємо, що ймовірність обрати у вибірку пару з відстанню, меншою за , щонайменше (приблизно)
тож імовірність того, що хоча б одну таку пару буде обрано протягом раундів (і тому буде знайдено менше ), дорівнює
(ми скористалися тим, що для будь-якого дійсного числа , див. нерівності Бернуллі).
Зауважимо, що це прямує до експоненційно зі зростанням . Це натякає, що буде малим для погано обраного .
Ми показали, що , або, що рівносильно, . Нам потрібно знати , щоб мати змогу оцінити її сподіване значення. Зауважимо, що . Це тому, що зменшення квадратів лише зменшує кількість точок у кожному квадраті (розщеплює точки на інші квадрати), і це продовжує зменшувати суму квадратів. Отже,
(ми скористалися тим, що , див. доведення на Stackexchange).
Нарешті, , і сподіваний час роботи дорівнює , з розумним сталим множником.
Реалізація алгоритму
Перевага цього алгоритму в тому, що його прямолінійно реалізувати, але він усе ж має добру швидкодію на практиці. Спочатку ми беремо вибірку з відстаней і задаємо як мінімум цих відстаней. Потім ми вставляємо точки у «блоки» за допомогою хеш-таблиці з 2D-координат у вектор точок. Нарешті, просто обчислюємо відстані між парами одного блока та парами сусідніх блоків. Операції з хеш-таблицею мають сподіваний час, і тому наш алгоритм зберігає сподіваний час зі збільшеною сталою.
Перегляньте це надсилання до Library Checker.
- C++
- Python
- TypeScript
- Go
#include <bits/stdc++.h>
using namespace std;
using ll = long long;
using ld = long double;
struct pt {
ll x, y;
pt() {}
pt(ll x_, ll y_) : x(x_), y(y_) {}
void read() {
cin >> x >> y;
}
};
bool operator==(const pt& a, const pt& b) {
return a.x == b.x and a.y == b.y;
}
struct CustomHashPoint {
size_t operator()(const pt& p) const {
static const uint64_t C = chrono::steady_clock::now().time_since_epoch().count();
return C ^ ((p.x << 32) ^ p.y);
}
};
ll dist2(pt a, pt b) {
ll dx = a.x - b.x;
ll dy = a.y - b.y;
return dx*dx + dy*dy;
}
pair<int,int> closest_pair_of_points(vector<pt> P) {
int n = int(P.size());
assert(n >= 2);
// якщо є дубльована точка, то ми маємо розв'язок
unordered_map<pt,int,CustomHashPoint> previous;
for (int i = 0; i < int(P.size()); ++i) {
auto it = previous.find(P[i]);
if (it != previous.end()) {
return {it->second, i};
}
previous[P[i]] = i;
}
unordered_map<pt,vector<int>,CustomHashPoint> grid;
grid.reserve(n);
mt19937 rd(chrono::system_clock::now().time_since_epoch().count());
uniform_int_distribution<int> dis(0, n-1);
ll d2 = dist2(P[0], P[1]);
pair<int,int> closest = {0, 1};
auto candidate_closest = [&](int i, int j) -> void {
ll ab2 = dist2(P[i], P[j]);
if (ab2 < d2) {
d2 = ab2;
closest = {i, j};
}
};
for (int i = 0; i < n; ++i) {
int j = dis(rd);
int k = dis(rd);
while (j == k) k = dis(rd);
candidate_closest(j, k);
}
ll d = ll( sqrt(ld(d2)) + 1 );
for (int i = 0; i < n; ++i) {
grid[{P[i].x/d, P[i].y/d}].push_back(i);
}
// той самий блок
for (const auto& it : grid) {
int k = int(it.second.size());
for (int i = 0; i < k; ++i) {
for (int j = i+1; j < k; ++j) {
candidate_closest(it.second[i], it.second[j]);
}
}
}
// сусідні блоки
for (const auto& it : grid) {
auto coord = it.first;
for (int dx = 0; dx <= 1; ++dx) {
for (int dy = -1; dy <= 1; ++dy) {
if (dx == 0 and dy == 0) continue;
pt neighbour = pt(
coord.x + dx,
coord.y + dy
);
for (int i : it.second) {
if (not grid.count(neighbour)) continue;
for (int j : grid.at(neighbour)) {
candidate_closest(i, j);
}
}
}
}
}
return closest;
}
import math
import random
def dist2(a: tuple[int, int], b: tuple[int, int]) -> int:
dx = a[0] - b[0]
dy = a[1] - b[1]
return dx * dx + dy * dy
def closest_pair_of_points(P: list[tuple[int, int]]) -> tuple[int, int]:
n = len(P)
assert n >= 2
# якщо є дубльована точка, то ми маємо розв'язок
previous: dict[tuple[int, int], int] = {}
for i, p in enumerate(P):
if p in previous:
return (previous[p], i)
previous[p] = i
d2 = dist2(P[0], P[1])
closest = (0, 1)
def candidate_closest(i: int, j: int) -> None:
nonlocal d2, closest
ab2 = dist2(P[i], P[j])
if ab2 < d2:
d2 = ab2
closest = (i, j)
# вибірка з n випадкових пар, щоб оцінити мінімальну відстань
for _ in range(n):
j = random.randrange(n)
k = random.randrange(n)
while j == k:
k = random.randrange(n)
candidate_closest(j, k)
d = int(math.isqrt(d2)) + 1
# розкладаємо точки у блоки d x d
grid: dict[tuple[int, int], list[int]] = {}
for i, p in enumerate(P):
grid.setdefault((p[0] // d, p[1] // d), []).append(i)
# той самий блок
for bucket in grid.values():
k = len(bucket)
for i in range(k):
for j in range(i + 1, k):
candidate_closest(bucket[i], bucket[j])
# сусідні блоки
for coord, bucket in grid.items():
for dx in range(0, 2):
for dy in range(-1, 2):
if dx == 0 and dy == 0:
continue
neighbour = (coord[0] + dx, coord[1] + dy)
if neighbour not in grid:
continue
for i in bucket:
for j in grid[neighbour]:
candidate_closest(i, j)
return closest
function dist2(a: [number, number], b: [number, number]): number {
const dx = a[0] - b[0];
const dy = a[1] - b[1];
return dx * dx + dy * dy;
}
function closestPairOfPoints(P: [number, number][]): [number, number] {
const n = P.length;
if (n < 2) throw new Error("потрібно щонайменше 2 точки");
// якщо є дубльована точка, то ми маємо розв'язок
const previous = new Map<string, number>();
for (let i = 0; i < n; ++i) {
const key = P[i][0] + "," + P[i][1];
const seen = previous.get(key);
if (seen !== undefined) return [seen, i];
previous.set(key, i);
}
let d2 = dist2(P[0], P[1]);
let closest: [number, number] = [0, 1];
const candidateClosest = (i: number, j: number): void => {
const ab2 = dist2(P[i], P[j]);
if (ab2 < d2) {
d2 = ab2;
closest = [i, j];
}
};
// вибірка з n випадкових пар, щоб оцінити мінімальну відстань
const rnd = () => Math.floor(Math.random() * n);
for (let i = 0; i < n; ++i) {
const j = rnd();
let k = rnd();
while (j === k) k = rnd();
candidateClosest(j, k);
}
const d = Math.floor(Math.sqrt(d2)) + 1;
// розкладаємо точки у блоки d x d
const grid = new Map<string, number[]>();
const cell = (x: number, y: number) => Math.floor(x / d) + "," + Math.floor(y / d);
for (let i = 0; i < n; ++i) {
const key = cell(P[i][0], P[i][1]);
if (!grid.has(key)) grid.set(key, []);
grid.get(key)!.push(i);
}
// той самий блок
for (const bucket of grid.values()) {
const k = bucket.length;
for (let i = 0; i < k; ++i)
for (let j = i + 1; j < k; ++j)
candidateClosest(bucket[i], bucket[j]);
}
// сусідні блоки
for (const [key, bucket] of grid) {
const [cx, cy] = key.split(",").map(Number);
for (let dx = 0; dx <= 1; ++dx) {
for (let dy = -1; dy <= 1; ++dy) {
if (dx === 0 && dy === 0) continue;
const nKey = (cx + dx) + "," + (cy + dy);
const nb = grid.get(nKey);
if (nb === undefined) continue;
for (const i of bucket)
for (const j of nb)
candidateClosest(i, j);
}
}
}
return closest;
}
package main
import (
"math"
"math/rand"
)
type point struct {
x, y int64
}
func dist2(a, b point) int64 {
dx := a.x - b.x
dy := a.y - b.y
return dx*dx + dy*dy
}
type cell struct {
cx, cy int64
}
func closestPairOfPoints(P []point) (int, int) {
n := len(P)
if n < 2 {
panic("потрібно щонайменше 2 точки")
}
// якщо є дубльована точка, то ми маємо розв'язок
previous := make(map[point]int, n)
for i, p := range P {
if seen, ok := previous[p]; ok {
return seen, i
}
previous[p] = i
}
d2 := dist2(P[0], P[1])
closest := [2]int{0, 1}
candidateClosest := func(i, j int) {
ab2 := dist2(P[i], P[j])
if ab2 < d2 {
d2 = ab2
closest = [2]int{i, j}
}
}
// вибірка з n випадкових пар, щоб оцінити мінімальну відстань
for i := 0; i < n; i++ {
j := rand.Intn(n)
k := rand.Intn(n)
for j == k {
k = rand.Intn(n)
}
candidateClosest(j, k)
}
d := int64(math.Sqrt(float64(d2))) + 1
// розкладаємо точки у блоки d x d
grid := make(map[cell][]int)
for i, p := range P {
c := cell{floorDiv(p.x, d), floorDiv(p.y, d)}
grid[c] = append(grid[c], i)
}
// той самий блок
for _, bucket := range grid {
k := len(bucket)
for i := 0; i < k; i++ {
for j := i + 1; j < k; j++ {
candidateClosest(bucket[i], bucket[j])
}
}
}
// сусідні блоки
for coord, bucket := range grid {
for dx := int64(0); dx <= 1; dx++ {
for dy := int64(-1); dy <= 1; dy++ {
if dx == 0 && dy == 0 {
continue
}
neighbour := cell{coord.cx + dx, coord.cy + dy}
nb, ok := grid[neighbour]
if !ok {
continue
}
for _, i := range bucket {
for _, j := range nb {
candidateClosest(i, j)
}
}
}
}
}
return closest[0], closest[1]
}
// Цілочисельне ділення з округленням донизу (для від'ємних координат).
func floorDiv(a, b int64) int64 {
q := a / b
if (a%b != 0) && ((a < 0) != (b < 0)) {
q--
}
return q
}
Альтернативний рандомізований алгоритм з лінійним сподіваним часом
Тепер ми наводимо інший рандомізований алгоритм, який менш практичний, але для якого дуже легко показати, що він працює за сподіваний лінійний час.
- Випадково переставимо точок
- Візьмемо
- Розіб'ємо площину на квадрати зі стороною
- Для :
- Беремо квадрат, що відповідає
- Перебираємо квадратів у межах двох кроків до нашого квадрата в сітці квадратів, що розбиває площину
- Якщо деяка у тих квадратах має , то
- Перераховуємо розбиття та квадрати з
- Зберігаємо точки у відповідних квадратах
- інакше зберігаємо у відповідному квадраті
- виводимо
Коректність випливає з того, що в будь-який момент ми вже маємо деяку пару з відстанню , тож ми намагаємося знайти лише нові пари з відстанню, меншою за . Оскільки кожен квадрат має сторону , кандидатна пара може бути щонайбільше на відстані квадратів, тож для заданої точки ми перевіряємо кандидатів у навколишніх квадратах. Будь-яка точка у квадраті, розташованому далі, завжди даватиме відстань, більшу за .
Хоча цей алгоритм може виглядати повільним через багаторазовий перерахунок усього, ми можемо показати, що повна сподівана вартість є лінійною.
Доведення
Нехай — випадкова величина, що дорівнює , коли точка спричиняє зміну і перерахунок структур даних, і — якщо ні. Легко показати, що вартість дорівнює , оскільки на -му кроці ми розглядаємо лише перші точок. Однак виявляється, що . Це тому, що на -му кроці — це відстань найближчої пари в , а — це ймовірність того, що належить найближчій парі, що трапляється лише в парах з можливих пар (за припущення, що всі відстані різні), тож імовірність щонайбільше , оскільки ми попередньо перемішали точки рівномірно.
Тому ми можемо побачити, що сподівана вартість дорівнює
Узагальнення: пошук трикутника з мінімальним периметром
Описаний вище алгоритм цікаво узагальнюється на таку задачу: серед заданої множини точок обрати три різні точки так, щоб сума попарних відстаней між ними була найменшою.
Насправді для розв'язання цієї задачі алгоритм залишається тим самим: ми ділимо поле на дві половини вертикальною прямою, рекурсивно викликаємо розв'язок на обох половинах, обираємо мінімум зі знайдених периметрів, будуємо смугу завтовшки і перебираємо всі трикутники, що можуть покращити відповідь. (Зауважимо, що трикутник з периметром має найдовшу сторону .)
Задачі для практики
- UVA 10245 "The Closest Pair Problem" [difficulty: low]
- SPOJ #8725 CLOPPAIR "Closest Point Pair" [difficulty: low]
- CODEFORCES Team Olympiad Saratov - 2011 "Minimum amount" [difficulty: medium]
- Google CodeJam 2009 Final "Min Perimeter" [difficulty: medium]
- SPOJ #7029 CLOSEST "Closest Triple" [difficulty: medium]
- TIMUS 1514 National Park [difficulty: medium]