Пошук пари відрізків, що перетинаються
Задано відрізків на площині. Потрібно перевірити, чи перетинаються хоча б два з них між собою. Якщо відповідь так, то вивести цю пару відрізків, що перетинаються; якщо відповідей кілька, достатньо вибрати будь-яку з них.
Наївний алгоритм розв'язання — перебрати всі пари відрізків за і для кожної пари перевірити, чи перетинаються вони. У цій статті описано алгоритм зі складністю , який ґрунтується на методі замітальної прямої.
- Відрізків багато ( великий), і перебір усіх пар за занадто повільний?
- Тобі треба знайти перетин серед множини відрізків, а не перевірити одну конкретну пару? (якщо ні → Перевірка перетину двох відрізків)
- Достатньо знайти будь-яку одну пару, що перетинається (а не всі точки перетину)?
Алгоритм
Подумки проведемо вертикальну пряму і почнемо рухати цю пряму вправо. Під час свого руху ця пряма зустрічатиметься з відрізками, і щоразу, коли відрізок перетинає нашу пряму, він перетинає її рівно в одній точці (вважатимемо, що вертикальних відрізків немає).
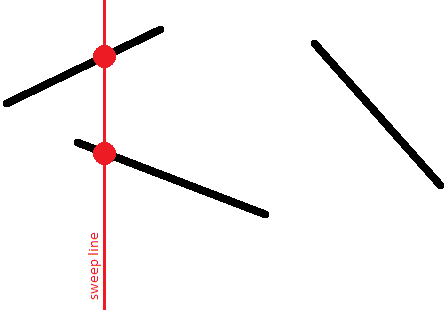
Отже, для кожного відрізка в якийсь момент часу його точка з'явиться на замітальній прямій, потім із рухом прямої ця точка рухатиметься, і нарешті в якийсь момент відрізок зникне з прямої.
Нас цікавить відносний порядок відрізків уздовж вертикалі. А саме, ми зберігатимемо список відрізків, що перетинають замітальну пряму в заданий момент, де відрізки відсортовані за їхньою -координатою на замітальній прямій.
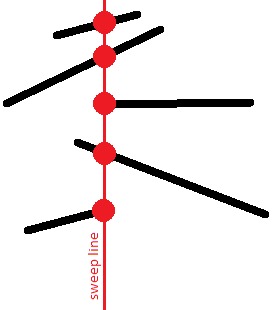
Цей порядок цікавий тим, що відрізки, які перетинаються, матимуть однакову -координату принаймні в один момент часу:
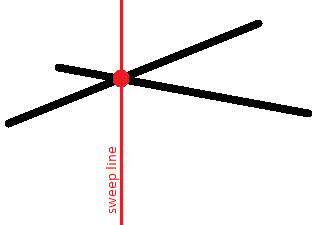
Сформулюємо ключові твердження:
- Щоб знайти пару відрізків, що перетинаються, достатньо розглядати лише сусідні відрізки при кожному фіксованому положенні замітальної прямої.
- Достатньо розглядати замітальну пряму не в усіх можливих дійсних положеннях , а лише в тих положеннях, коли з'являються нові відрізки або зникають старі. Інакше кажучи, достатньо обмежитися лише положеннями, що дорівнюють абсцисам кінцевих точок відрізків.
- Коли з'являється новий відрізок, достатньо вставити його у потрібне місце списку, отриманого для попереднього положення замітальної прямої. Нам потрібно лише перевірити перетин доданого відрізка з його безпосередніми сусідами у списку зверху та знизу.
- Якщо відрізок зникає, достатньо вилучити його з поточного списку. Після цього необхідно перевірити перетин верхнього та нижнього сусідів у списку.
- Інших змін у послідовності відрізків у списку, крім описаних, не існує. Жодних інших перевірок на перетин не потрібно.
Щоб зрозуміти істинність цих тверджень, достатньо таких зауважень:
- Два відрізки, що не перетинаються, ніколи не змінюють свого відносного порядку.
Справді, якщо один відрізок спочатку був вищим за інший, а потім став нижчим, то між цими двома моментами відбувся перетин цих двох відрізків. - Два відрізки, що не перетинаються, також не можуть мати однакові -координати.
- Звідси випливає, що в момент появи відрізка ми можемо знайти позицію для цього відрізка в черзі, і нам більше не доведеться переставляти цей відрізок у черзі: його порядок відносно інших відрізків у черзі не зміниться.
- Два відрізки, що перетинаються, у момент їхньої точки перетину будуть сусідами один одного в черзі.
- Тому для пошуку пар відрізків, що перетинаються, достатньо перевірити перетин усіх і лише тих пар відрізків, які колись під час руху замітальної прямої хоча б раз були сусідами один одного.
Легко помітити, що достатньо лише перевірити доданий відрізок з його верхнім і нижнім сусідами, а також при вилученні відрізка — його верхнього і нижнього сусіда (які після вилучення стануть сусідами один одного). - Слід зауважити, що при фіксованому положенні замітальної прямої ми маємо спочатку додати всі відрізки, що починаються в цій x-координаті, і лише потім вилучити всі відрізки, що тут закінчуються.
Таким чином, ми не пропускаємо перетин відрізків у вершині: тобто такі випадки, коли два відрізки мають спільну вершину. - Зауважимо, що вертикальні відрізки насправді не впливають на коректність алгоритму.
Ці відрізки відрізняються тим, що з'являються і зникають одночасно. Однак завдяки попередньому зауваженню ми знаємо, що всі відрізки спочатку будуть додані до черги, і лише потім будуть вилучені. Тому, якщо вертикальний відрізок перетинається з якимось іншим відрізком, відкритим у той момент (зокрема й вертикальним), це буде виявлено.
У яке місце черги поставити вертикальні відрізки? Адже вертикальний відрізок не має однієї конкретної -координати, він тягнеться вздовж цілого відрізка по -координаті. Однак легко зрозуміти, що за -координату можна взяти будь-яку координату з цього відрізка.
Таким чином, увесь алгоритм виконає не більше ніж перевірок на перетин пари відрізків, і виконає операцій із чергою відрізків ( операцій у момент появи та зникнення кожного відрізка).
Підсумкова асимптотична поведінка алгоритму отже становить .
Реалізація
Наведемо повну реалізацію описаного алгоритму:
- C++
- Python
- TypeScript
- Go
const double EPS = 1E-9;
struct pt {
double x, y;
};
struct seg {
pt p, q;
int id;
double get_y(double x) const {
if (abs(p.x - q.x) < EPS)
return p.y;
return p.y + (q.y - p.y) * (x - p.x) / (q.x - p.x);
}
};
bool intersect1d(double l1, double r1, double l2, double r2) {
if (l1 > r1)
swap(l1, r1);
if (l2 > r2)
swap(l2, r2);
return max(l1, l2) <= min(r1, r2) + EPS;
}
int vec(const pt& a, const pt& b, const pt& c) {
double s = (b.x - a.x) * (c.y - a.y) - (b.y - a.y) * (c.x - a.x);
return abs(s) < EPS ? 0 : s > 0 ? +1 : -1;
}
bool intersect(const seg& a, const seg& b)
{
return intersect1d(a.p.x, a.q.x, b.p.x, b.q.x) &&
intersect1d(a.p.y, a.q.y, b.p.y, b.q.y) &&
vec(a.p, a.q, b.p) * vec(a.p, a.q, b.q) <= 0 &&
vec(b.p, b.q, a.p) * vec(b.p, b.q, a.q) <= 0;
}
bool operator<(const seg& a, const seg& b)
{
double x = max(min(a.p.x, a.q.x), min(b.p.x, b.q.x));
return a.get_y(x) < b.get_y(x) - EPS;
}
struct event {
double x;
int tp, id;
event() {}
event(double x, int tp, int id) : x(x), tp(tp), id(id) {}
bool operator<(const event& e) const {
if (abs(x - e.x) > EPS)
return x < e.x;
return tp > e.tp;
}
};
set<seg> s;
vector<set<seg>::iterator> where;
set<seg>::iterator prev(set<seg>::iterator it) {
return it == s.begin() ? s.end() : --it;
}
set<seg>::iterator next(set<seg>::iterator it) {
return ++it;
}
pair<int, int> solve(const vector<seg>& a) {
int n = (int)a.size();
vector<event> e;
for (int i = 0; i < n; ++i) {
e.push_back(event(min(a[i].p.x, a[i].q.x), +1, i));
e.push_back(event(max(a[i].p.x, a[i].q.x), -1, i));
}
sort(e.begin(), e.end());
s.clear();
where.resize(a.size());
for (size_t i = 0; i < e.size(); ++i) {
int id = e[i].id;
if (e[i].tp == +1) {
set<seg>::iterator nxt = s.lower_bound(a[id]), prv = prev(nxt);
if (nxt != s.end() && intersect(*nxt, a[id]))
return make_pair(nxt->id, id);
if (prv != s.end() && intersect(*prv, a[id]))
return make_pair(prv->id, id);
where[id] = s.insert(nxt, a[id]);
} else {
set<seg>::iterator nxt = next(where[id]), prv = prev(where[id]);
if (nxt != s.end() && prv != s.end() && intersect(*nxt, *prv))
return make_pair(prv->id, nxt->id);
s.erase(where[id]);
}
}
return make_pair(-1, -1);
}
from bisect import insort
EPS = 1e-9
class Pt:
def __init__(self, x: float, y: float):
self.x = x
self.y = y
class Seg:
def __init__(self, p: Pt, q: Pt, idx: int):
self.p = p
self.q = q
self.id = idx
def get_y(self, x: float) -> float:
if abs(self.p.x - self.q.x) < EPS:
return self.p.y
return self.p.y + (self.q.y - self.p.y) * (x - self.p.x) / (self.q.x - self.p.x)
def intersect1d(l1: float, r1: float, l2: float, r2: float) -> bool:
if l1 > r1:
l1, r1 = r1, l1
if l2 > r2:
l2, r2 = r2, l2
return max(l1, l2) <= min(r1, r2) + EPS
def vec(a: Pt, b: Pt, c: Pt) -> int:
s = (b.x - a.x) * (c.y - a.y) - (b.y - a.y) * (c.x - a.x)
return 0 if abs(s) < EPS else (1 if s > 0 else -1)
def intersect(a: Seg, b: Seg) -> bool:
return (intersect1d(a.p.x, a.q.x, b.p.x, b.q.x) and
intersect1d(a.p.y, a.q.y, b.p.y, b.q.y) and
vec(a.p, a.q, b.p) * vec(a.p, a.q, b.q) <= 0 and
vec(b.p, b.q, a.p) * vec(b.p, b.q, a.q) <= 0)
def seg_less(a: Seg, b: Seg) -> bool:
# порядок відрізків уздовж замітальної прямої (аналог operator< у C++)
x = max(min(a.p.x, a.q.x), min(b.p.x, b.q.x))
return a.get_y(x) < b.get_y(x) - EPS
# Примітка щодо структури даних:
# у C++ використано std::set<seg> з компаратором, що залежить від поточного
# положення прямої, а позиції зберігаються через ітератори (prev/next).
# У Python немає збалансованого дерева з довільним компаратором у stdlib;
# SortedList з sortedcontainers (стандарт CP) теж потребує статичного ключа,
# а тут порядок «ковзний». Тому тримаємо звичайний список `s`, відсортований
# за seg_less, і робимо нижню межу бінарним пошуком. Вставка/вилучення за
# індексом — це O(n) (зсув списку), отже загальна складність стає O(n^2);
# логіка алгоритму (сусіди при вставці/вилученні) збережена байт-у-байт.
def solve(a: list[Seg]) -> tuple[int, int]:
n = len(a)
# подія: (x, tp, id); tp=+1 — поява, tp=-1 — зникнення
events = []
for i in range(n):
events.append((min(a[i].p.x, a[i].q.x), +1, i))
events.append((max(a[i].p.x, a[i].q.x), -1, i))
def event_key(e):
# спершу за x, при рівних x — спершу всі появи (tp=+1), потім зникнення
return (e[0], -e[1])
events.sort(key=event_key)
s: list[Seg] = [] # відрізки, відсортовані за seg_less
where = [0] * n # індекс відрізка в s (аналог ітератора з C++)
def lower_bound(seg: Seg) -> int:
lo, hi = 0, len(s)
while lo < hi:
mid = (lo + hi) // 2
if seg_less(s[mid], seg):
lo = mid + 1
else:
hi = mid
return lo
for x, tp, idx in events:
if tp == +1:
pos = lower_bound(a[idx])
if pos < len(s) and intersect(s[pos], a[idx]): # верхній сусід
return (s[pos].id, idx)
if pos > 0 and intersect(s[pos - 1], a[idx]): # нижній сусід
return (s[pos - 1].id, idx)
s.insert(pos, a[idx])
where[idx] = pos
for j in range(pos + 1, len(s)): # оновлюємо індекси правіше вставки
where[s[j].id] = j
else:
pos = where[idx]
has_nxt = pos + 1 < len(s)
has_prv = pos > 0
if has_nxt and has_prv and intersect(s[pos + 1], s[pos - 1]):
return (s[pos - 1].id, s[pos + 1].id)
s.pop(pos)
for j in range(pos, len(s)): # оновлюємо індекси правіше вилучення
where[s[j].id] = j
return (-1, -1)
const EPS = 1e-9;
interface Pt {
x: number;
y: number;
}
class Seg {
constructor(public p: Pt, public q: Pt, public id: number) {}
getY(x: number): number {
if (Math.abs(this.p.x - this.q.x) < EPS) return this.p.y;
return this.p.y + ((this.q.y - this.p.y) * (x - this.p.x)) / (this.q.x - this.p.x);
}
}
function intersect1d(l1: number, r1: number, l2: number, r2: number): boolean {
if (l1 > r1) [l1, r1] = [r1, l1];
if (l2 > r2) [l2, r2] = [r2, l2];
return Math.max(l1, l2) <= Math.min(r1, r2) + EPS;
}
function vec(a: Pt, b: Pt, c: Pt): number {
const s = (b.x - a.x) * (c.y - a.y) - (b.y - a.y) * (c.x - a.x);
return Math.abs(s) < EPS ? 0 : s > 0 ? 1 : -1;
}
function intersect(a: Seg, b: Seg): boolean {
return (
intersect1d(a.p.x, a.q.x, b.p.x, b.q.x) &&
intersect1d(a.p.y, a.q.y, b.p.y, b.q.y) &&
vec(a.p, a.q, b.p) * vec(a.p, a.q, b.q) <= 0 &&
vec(b.p, b.q, a.p) * vec(b.p, b.q, a.q) <= 0
);
}
// порядок відрізків уздовж замітальної прямої (аналог operator< у C++)
function segLess(a: Seg, b: Seg): boolean {
const x = Math.max(Math.min(a.p.x, a.q.x), Math.min(b.p.x, b.q.x));
return a.getY(x) < b.getY(x) - EPS;
}
// У стандартній бібліотеці TS немає збалансованого дерева з довільним
// компаратором, а порядок тут «ковзний» (залежить від положення прямої),
// тому std::set замінюємо відсортованим масивом `s` з бінарним пошуком
// нижньої межі. Вставка/вилучення за індексом — O(n), отже загальна
// складність O(n^2); логіка сусідів збережена байт-у-байт.
function solve(a: Seg[]): [number, number] {
const n = a.length;
// подія: [x, tp, id]; tp=+1 — поява, tp=-1 — зникнення
const events: [number, number, number][] = [];
for (let i = 0; i < n; i++) {
events.push([Math.min(a[i].p.x, a[i].q.x), +1, i]);
events.push([Math.max(a[i].p.x, a[i].q.x), -1, i]);
}
// спершу за x, при рівних x — спершу появи (tp=+1), потім зникнення
events.sort((e1, e2) => (Math.abs(e1[0] - e2[0]) > EPS ? e1[0] - e2[0] : e2[1] - e1[1]));
const s: Seg[] = []; // відрізки, відсортовані за segLess
const where = new Array<number>(n).fill(0); // індекс відрізка в s
const lowerBound = (seg: Seg): number => {
let lo = 0;
let hi = s.length;
while (lo < hi) {
const mid = (lo + hi) >> 1;
if (segLess(s[mid], seg)) lo = mid + 1;
else hi = mid;
}
return lo;
};
for (const [, tp, id] of events) {
if (tp === +1) {
const pos = lowerBound(a[id]);
if (pos < s.length && intersect(s[pos], a[id])) return [s[pos].id, id]; // верхній
if (pos > 0 && intersect(s[pos - 1], a[id])) return [s[pos - 1].id, id]; // нижній
s.splice(pos, 0, a[id]);
for (let j = pos; j < s.length; j++) where[s[j].id] = j;
} else {
const pos = where[id];
const hasNxt = pos + 1 < s.length;
const hasPrv = pos > 0;
if (hasNxt && hasPrv && intersect(s[pos + 1], s[pos - 1])) {
return [s[pos - 1].id, s[pos + 1].id];
}
s.splice(pos, 1);
for (let j = pos; j < s.length; j++) where[s[j].id] = j;
}
}
return [-1, -1];
}
package main
import (
"math"
"sort"
)
const eps = 1e-9
type Pt struct {
x, y float64
}
type Seg struct {
p, q Pt
id int
}
func (s Seg) getY(x float64) float64 {
if math.Abs(s.p.x-s.q.x) < eps {
return s.p.y
}
return s.p.y + (s.q.y-s.p.y)*(x-s.p.x)/(s.q.x-s.p.x)
}
func intersect1d(l1, r1, l2, r2 float64) bool {
if l1 > r1 {
l1, r1 = r1, l1
}
if l2 > r2 {
l2, r2 = r2, l2
}
return math.Max(l1, l2) <= math.Min(r1, r2)+eps
}
func vec(a, b, c Pt) int {
s := (b.x-a.x)*(c.y-a.y) - (b.y-a.y)*(c.x-a.x)
if math.Abs(s) < eps {
return 0
}
if s > 0 {
return 1
}
return -1
}
func intersect(a, b Seg) bool {
return intersect1d(a.p.x, a.q.x, b.p.x, b.q.x) &&
intersect1d(a.p.y, a.q.y, b.p.y, b.q.y) &&
vec(a.p, a.q, b.p)*vec(a.p, a.q, b.q) <= 0 &&
vec(b.p, b.q, a.p)*vec(b.p, b.q, a.q) <= 0
}
// порядок відрізків уздовж замітальної прямої (аналог operator< у C++)
func segLess(a, b Seg) bool {
x := math.Max(math.Min(a.p.x, a.q.x), math.Min(b.p.x, b.q.x))
return a.getY(x) < b.getY(x)-eps
}
// У stdlib Go немає збалансованого дерева з довільним компаратором, а порядок
// тут «ковзний» (залежить від положення прямої), тому std::set замінюємо
// відсортованим зрізом s з бінарним пошуком нижньої межі. Вставка/вилучення за
// індексом — O(n), отже загальна складність O(n^2); логіка сусідів збережена.
func solve(a []Seg) (int, int) {
n := len(a)
type event struct {
x float64
tp int // +1 — поява, -1 — зникнення
id int
}
events := make([]event, 0, 2*n)
for i := 0; i < n; i++ {
events = append(events, event{math.Min(a[i].p.x, a[i].q.x), +1, i})
events = append(events, event{math.Max(a[i].p.x, a[i].q.x), -1, i})
}
// спершу за x, при рівних x — спершу появи (tp=+1), потім зникнення
sort.Slice(events, func(i, j int) bool {
if math.Abs(events[i].x-events[j].x) > eps {
return events[i].x < events[j].x
}
return events[i].tp > events[j].tp
})
s := make([]Seg, 0, n) // відрізки, відсортовані за segLess
where := make([]int, n) // індекс відрізка в s
lowerBound := func(seg Seg) int {
lo, hi := 0, len(s)
for lo < hi {
mid := (lo + hi) / 2
if segLess(s[mid], seg) {
lo = mid + 1
} else {
hi = mid
}
}
return lo
}
for _, e := range events {
id := e.id
if e.tp == +1 {
pos := lowerBound(a[id])
if pos < len(s) && intersect(s[pos], a[id]) { // верхній сусід
return s[pos].id, id
}
if pos > 0 && intersect(s[pos-1], a[id]) { // нижній сусід
return s[pos-1].id, id
}
s = append(s, Seg{})
copy(s[pos+1:], s[pos:])
s[pos] = a[id]
for j := pos; j < len(s); j++ {
where[s[j].id] = j
}
} else {
pos := where[id]
hasNxt := pos+1 < len(s)
hasPrv := pos > 0
if hasNxt && hasPrv && intersect(s[pos+1], s[pos-1]) {
return s[pos-1].id, s[pos+1].id
}
s = append(s[:pos], s[pos+1:]...)
for j := pos; j < len(s); j++ {
where[s[j].id] = j
}
}
}
return -1, -1
}
Головна функція тут — solve(), яка повертає відрізки, що перетинаються, якщо такі існують, або , якщо перетинів немає.
Перевірка перетину двох відрізків виконується функцією intersect (), що використовує алгоритм на основі орієнтованої площі трикутника.
Черга відрізків — це глобальна змінна s, тип set<event>. Ітератори, що задають позицію кожного відрізка в черзі (для зручного вилучення відрізків із черги), зберігаються у глобальному масиві where.
Також уведено дві допоміжні функції prev() і next(), які повертають ітератори на попередній та наступний елементи (або end(), якщо такого не існує).
Константа EPS позначає похибку порівняння двох дійсних чисел (вона переважно використовується при перевірці двох відрізків на перетин).