Система неперетинних множин
У цій статті ми обговоримо структуру даних система неперетинних множин (СНМ, англ. DSU). Часто її також називають Union Find через дві її основні операції.
Ця структура даних надає такі можливості. Нам дано кілька елементів, кожен з яких є окремою множиною. СНМ матиме операцію об'єднання будь-яких двох множин, а також зможе сказати, у якій множині знаходиться певний елемент. Класична версія також вводить третю операцію — вона може створити множину з нового елемента.
Отже, базовий інтерфейс цієї структури даних складається лише з трьох операцій:
make_set(v)— створює нову множину, що складається з нового елементаvunion_sets(a, b)— об'єднує дві вказані множини (множину, у якій знаходиться елементa, і множину, у якій знаходиться елементb)find_set(v)— повертає представника множини (англ. representative, його ще називають лідером, leader), яка містить елементv. Цей представник є елементом відповідної множини. Його обирає в кожній множині сама структура даних (і він може змінюватися з часом, а саме після викликівunion_sets). Цього представника можна використовувати, щоб перевірити, чи належать два елементи одній множині, чи ні.aіbзнаходяться рівно в одній множині, якщоfind_set(a) == find_set(b). Інакше вони знаходяться в різних множинах.
Як буде детальніше описано далі, ця структура даних дозволяє виконувати кожну з цих операцій майже за час у середньому.
Також в одному з підрозділів пояснюється альтернативна структура СНМ, яка досягає повільнішої середньої складності , але може бути потужнішою за звичайну структуру СНМ.
- Чи потрібно динамічно об'єднувати множини (компоненти) й додавати ребра під час роботи? (якщо ні, граф статичний → достатньо одного пошуку в глибину для компонент зв'язності)
- Чи достатньо лише об'єднувати (union) і запитувати належність, без видалення ребер? (якщо потрібні й видалення → видалення зі структури за )
- Чи зводиться задача до групування елементів за відношенням еквівалентності (компоненти, цикли, спільні множини)?
Побудова ефективної структури даних
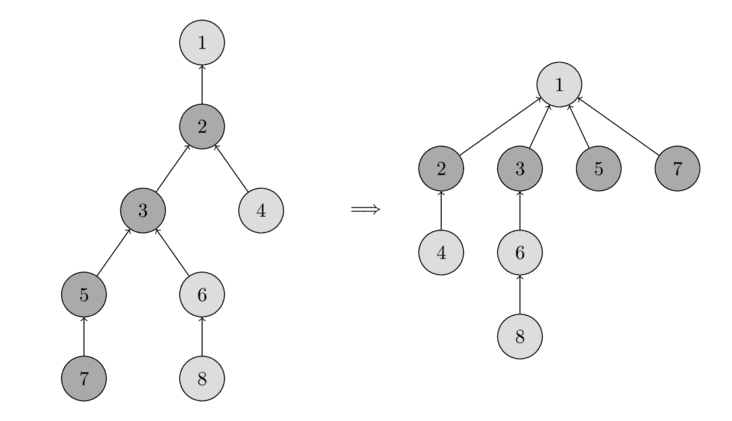
Ми зберігатимемо множини у вигляді дерев: кожне дерево відповідатиме одній множині. А корінь дерева буде представником/лідером множини.
На наступному зображенні ви можете побачити представлення таких дерев.

На початку кожен елемент є окремою множиною, тому кожна вершина є власним деревом. Потім ми об'єднуємо множину, що містить елемент 1, і множину, що містить елемент 2. Потім ми об'єднуємо множину, що містить елемент 3, і множину, що містить елемент 4. А на останньому кроці ми об'єднуємо множину, що містить елемент 1, і множину, що містить елемент 3.
Для реалізації це означає, що нам доведеться підтримувати масив parent, який зберігає посилання на безпосереднього предка у дереві.
Наївна реалізація
Ми вже можемо написати першу реалізацію структури даних система неперетинних множин. Спочатку вона буде досить неефективною, але згодом ми зможемо покращити її за допомогою двох оптимізацій, так що кожен виклик функції займатиме майже сталий час.
Як ми вже казали, уся інформація про множини елементів зберігатиметься в масиві parent.
Щоб створити нову множину (операція make_set(v)), ми просто створюємо дерево з коренем у вершині v, тобто вона є власним предком.
Щоб об'єднати дві множини (операція union_sets(a, b)), ми спочатку знаходимо представника множини, у якій знаходиться a, і представника множини, у якій знаходиться b.
Якщо представники однакові, то нам нічого робити — множини вже об'єднані.
Інакше ми можемо просто вказати, що один з представників є батьком іншого представника — тим самим об'єднуючи два дерева.
Нарешті, реалізація функції пошуку представника (операція find_set(v)):
ми просто піднімаємося предками вершини v, доки не досягнемо кореня, тобто такої вершини, посилання на предка якої веде до неї самої.
Цю операцію легко реалізувати рекурсивно.
- C++
- Python
- TypeScript
- Go
void make_set(int v) {
parent[v] = v;
}
int find_set(int v) {
if (v == parent[v])
return v;
return find_set(parent[v]);
}
void union_sets(int a, int b) {
a = find_set(a);
b = find_set(b);
if (a != b)
parent[b] = a;
}
def make_set(v):
parent[v] = v
def find_set(v):
if v == parent[v]:
return v
return find_set(parent[v])
def union_sets(a, b):
a = find_set(a)
b = find_set(b)
if a != b:
parent[b] = a
function makeSet(v: number): void {
parent[v] = v;
}
function findSet(v: number): number {
if (v === parent[v]) return v;
return findSet(parent[v]);
}
function unionSets(a: number, b: number): void {
a = findSet(a);
b = findSet(b);
if (a !== b) parent[b] = a;
}
func makeSet(v int) {
parent[v] = v
}
func findSet(v int) int {
if v == parent[v] {
return v
}
return findSet(parent[v])
}
func unionSets(a, b int) {
a = findSet(a)
b = findSet(b)
if a != b {
parent[b] = a
}
}
Однак ця реалізація неефективна.
Легко побудувати приклад, у якому дерева вироджуються в довгі ланцюги.
У такому випадку кожен виклик find_set(v) може займати часу.
Це далеко від складності, яку ми хочемо мати (майже сталий час). Тому ми розглянемо дві оптимізації, які дозволять суттєво пришвидшити роботу.
Оптимізація стискання шляхів
Ця оптимізація призначена для пришвидшення find_set.
Якщо ми викликаємо find_set(v) для деякої вершини v, то насправді ми знаходимо представника p для всіх вершин, які відвідуємо на шляху між v і справжнім представником p.
Прийом полягає в тому, щоб зробити шляхи для всіх цих вершин коротшими, встановивши батька кожної відвіданої вершини безпосередньо рівним p.
Ви можете побачити цю операцію на наступному зображенні.
Ліворуч розташоване дерево, а праворуч — стиснуте дерево після виклику find_set(7), який скорочує шляхи для відвіданих вершин 7, 5, 3 і 2.
Нова реалізація find_set виглядає так:
- C++
- Python
- TypeScript
- Go
int find_set(int v) {
if (v == parent[v])
return v;
return parent[v] = find_set(parent[v]);
}
# Рекурсивний варіант наочний, але в Python глибина рекурсії за замовчуванням
# обмежена ~1000 (sys.getrecursionlimit). На довгому ланцюзі find_set
# спричинить RecursionError ще до стискання шляху, тож для великих n
# безпечніше робити дві проходи ітеративно: спершу знаходимо корінь,
# потім переприв'язуємо всі вершини шляху напряму до нього.
def find_set(v):
root = v
while root != parent[root]:
root = parent[root]
while parent[v] != root:
parent[v], v = root, parent[v]
return root
// Ітеративний варіант: спершу шукаємо корінь, потім стискаємо шлях.
function findSet(v: number): number {
let root = v;
while (root !== parent[root]) root = parent[root];
while (parent[v] !== root) {
const next = parent[v];
parent[v] = root;
v = next;
}
return root;
}
// Ітеративний варіант: спершу шукаємо корінь, потім стискаємо шлях.
func findSet(v int) int {
root := v
for root != parent[root] {
root = parent[root]
}
for parent[v] != root {
parent[v], v = root, parent[v]
}
return root
}
Ця проста реалізація робить те, що було задумано: спочатку знаходить представника множини (кореневу вершину), а потім у процесі розкручування стека відвідані вершини приєднуються безпосередньо до представника.
Ця проста модифікація операції вже досягає часової складності на виклик у середньому (тут без доведення). Існує друга модифікація, яка зробить її ще швидшою.
Об'єднання за розміром / рангом
У цій оптимізації ми змінимо операцію union_set.
Точніше, ми змінимо те, яке дерево приєднується до іншого.
У наївній реалізації друге дерево завжди приєднувалося до першого.
На практиці це може призводити до дерев, що містять ланцюги довжиною .
За допомогою цієї оптимізації ми уникнемо цього, ретельно обираючи, яке дерево приєднати.
Існує багато можливих евристик, які можна використати. Найпопулярнішими є два наступні підходи: у першому підході ми використовуємо як ранг розмір дерев, а в другому — глибину дерева (точніше, верхню межу глибини дерева, оскільки глибина зменшуватиметься при застосуванні стискання шляхів).
В обох підходах суть оптимізації однакова: ми приєднуємо дерево з меншим рангом до дерева з більшим рангом.
Ось реалізація об'єднання за розміром:
- C++
- Python
- TypeScript
- Go
void make_set(int v) {
parent[v] = v;
size[v] = 1;
}
void union_sets(int a, int b) {
a = find_set(a);
b = find_set(b);
if (a != b) {
if (size[a] < size[b])
swap(a, b);
parent[b] = a;
size[a] += size[b];
}
}
def make_set(v):
parent[v] = v
size[v] = 1
def union_sets(a, b):
a = find_set(a)
b = find_set(b)
if a != b:
if size[a] < size[b]:
a, b = b, a # обмін через розпакування кортежу
parent[b] = a
size[a] += size[b]
function makeSet(v: number): void {
parent[v] = v;
size[v] = 1;
}
function unionSets(a: number, b: number): void {
a = findSet(a);
b = findSet(b);
if (a !== b) {
if (size[a] < size[b]) [a, b] = [b, a]; // обмін через деструктуризацію
parent[b] = a;
size[a] += size[b];
}
}
func makeSet(v int) {
parent[v] = v
size[v] = 1
}
func unionSets(a, b int) {
a = findSet(a)
b = findSet(b)
if a != b {
if size[a] < size[b] {
a, b = b, a // обмін через множинне присвоєння
}
parent[b] = a
size[a] += size[b]
}
}
А ось реалізація об'єднання за рангом на основі глибини дерев:
- C++
- Python
- TypeScript
- Go
void make_set(int v) {
parent[v] = v;
rank[v] = 0;
}
void union_sets(int a, int b) {
a = find_set(a);
b = find_set(b);
if (a != b) {
if (rank[a] < rank[b])
swap(a, b);
parent[b] = a;
if (rank[a] == rank[b])
rank[a]++;
}
}
# rank — вбудована назва відсутня, тож можна використовувати її напряму,
# але тут беремо rank_, щоб не плутати з ідіомами інших мов.
def make_set(v):
parent[v] = v
rank_[v] = 0
def union_sets(a, b):
a = find_set(a)
b = find_set(b)
if a != b:
if rank_[a] < rank_[b]:
a, b = b, a
parent[b] = a
if rank_[a] == rank_[b]:
rank_[a] += 1
function makeSet(v: number): void {
parent[v] = v;
rank[v] = 0;
}
function unionSets(a: number, b: number): void {
a = findSet(a);
b = findSet(b);
if (a !== b) {
if (rank[a] < rank[b]) [a, b] = [b, a];
parent[b] = a;
if (rank[a] === rank[b]) rank[a]++;
}
}
func makeSet(v int) {
parent[v] = v
rank[v] = 0
}
func unionSets(a, b int) {
a = findSet(a)
b = findSet(b)
if a != b {
if rank[a] < rank[b] {
a, b = b, a
}
parent[b] = a
if rank[a] == rank[b] {
rank[a]++
}
}
}
Обидві оптимізації еквівалентні з точки зору часової та просторової складності. Тож на практиці ви можете використовувати будь-яку з них.
Часова складність
Як зазначалося раніше, якщо ми поєднаємо обидві оптимізації — стискання шляхів з об'єднанням за розміром / рангом — то досягнемо майже сталого часу на запит. Виявляється, що остаточна амортизована часова складність становить , де — обернена функція Аккермана, яка зростає дуже повільно. Насправді вона зростає настільки повільно, що не перевищує для всіх розумних (приблизно ).
Амортизована складність — це загальний час на операцію, оцінений за послідовністю з кількох операцій. Ідея полягає в тому, щоб гарантувати загальний час усієї послідовності, водночас дозволяючи окремим операціям бути значно повільнішими за амортизований час. Наприклад, у нашому випадку окремий виклик у найгіршому випадку може займати , але якщо ми виконаємо таких викликів поспіль, то в підсумку отримаємо середній час .
Ми також не наводитимемо доведення цієї часової складності, оскільки воно досить довге та складне.
Також варто згадати, що СНМ з об'єднанням за розміром / рангом, але без стискання шляхів працює за час на запит.
Зв'язування за індексом / зв'язування підкиданням монети
І об'єднання за рангом, і об'єднання за розміром вимагають, щоб ви зберігали додаткові дані для кожної множини та підтримували ці значення під час кожної операції об'єднання. Існує також рандомізований алгоритм, який трохи спрощує операцію об'єднання: зв'язування за індексом.
Ми призначаємо кожній множині випадкове значення, яке називаємо індексом, і приєднуємо множину з меншим індексом до множини з більшим. Імовірно, що більша множина матиме більший індекс, ніж менша множина, тому ця операція тісно пов'язана з об'єднанням за розміром. Насправді можна довести, що ця операція має таку саму часову складність, як і об'єднання за розміром. Однак на практиці вона трохи повільніша за об'єднання за розміром.
Доведення складності та ще більше технік об'єднання ви можете знайти тут.
- C++
- Python
- TypeScript
- Go
void make_set(int v) {
parent[v] = v;
index[v] = rand();
}
void union_sets(int a, int b) {
a = find_set(a);
b = find_set(b);
if (a != b) {
if (index[a] < index[b])
swap(a, b);
parent[b] = a;
}
}
import random
# index — вбудована назва відсутня, але краще уникати затінення; беремо idx.
def make_set(v):
parent[v] = v
idx[v] = random.random() # випадкове значення в [0, 1)
def union_sets(a, b):
a = find_set(a)
b = find_set(b)
if a != b:
if idx[a] < idx[b]:
a, b = b, a
parent[b] = a
function makeSet(v: number): void {
parent[v] = v;
idx[v] = Math.random(); // випадкове значення в [0, 1)
}
function unionSets(a: number, b: number): void {
a = findSet(a);
b = findSet(b);
if (a !== b) {
if (idx[a] < idx[b]) [a, b] = [b, a];
parent[b] = a;
}
}
import "math/rand"
func makeSet(v int) {
parent[v] = v
idx[v] = rand.Int() // випадкове ціле
}
func unionSets(a, b int) {
a = findSet(a)
b = findSet(b)
if a != b {
if idx[a] < idx[b] {
a, b = b, a
}
parent[b] = a
}
}
Поширеною хибною думкою є те, що просто підкидання монети для вирішення того, яку множину ми приєднуємо до іншої, має таку саму складність. Однак це неправда. У статті, на яку є посилання вище, висувається гіпотеза, що зв'язування підкиданням монети в поєднанні зі стисканням шляхів має складність . А в замірах швидкодії воно працює набагато гірше за об'єднання за розміром/рангом або зв'язування за індексом.
- C++
- Python
- TypeScript
- Go
void union_sets(int a, int b) {
a = find_set(a);
b = find_set(b);
if (a != b) {
if (rand() % 2)
swap(a, b);
parent[b] = a;
}
}
import random
def union_sets(a, b):
a = find_set(a)
b = find_set(b)
if a != b:
if random.randint(0, 1): # підкидання монети
a, b = b, a
parent[b] = a
function unionSets(a: number, b: number): void {
a = findSet(a);
b = findSet(b);
if (a !== b) {
if (Math.random() < 0.5) [a, b] = [b, a]; // підкидання монети
parent[b] = a;
}
}
import "math/rand"
func unionSets(a, b int) {
a = findSet(a)
b = findSet(b)
if a != b {
if rand.Intn(2) == 1 { // підкидання монети
a, b = b, a
}
parent[b] = a
}
}
Застосування та різні покращення
У цьому розділі ми розглянемо кілька застосувань цієї структури даних, як тривіальні випадки використання, так і деякі покращення самої структури.
Компоненти зв'язності у графі
Це одне з очевидних застосувань СНМ.
Формально задача визначається так: Спочатку ми маємо порожній граф. Нам потрібно додавати вершини та неорієнтовані ребра, а також відповідати на запити виду — «чи знаходяться вершини і в одній компоненті зв'язності графа?»
Тут ми можемо безпосередньо застосувати цю структуру даних і отримати розв'язок, який обробляє додавання вершини або ребра та запит майже за сталий час у середньому.
Це застосування є досить важливим, оскільки майже така сама задача з'являється в алгоритмі Краскала для пошуку мінімального кістякового дерева. Використовуючи СНМ, ми можемо покращити складність до .
Пошук компонент зв'язності на зображенні
Одним із застосувань СНМ є така задача: є зображення з пікселів. Спочатку всі вони білі, але потім малюється кілька чорних пікселів. Ви хочете визначити розмір кожної білої компоненти зв'язності в підсумковому зображенні.
Для розв'язку ми просто проходимо по всіх білих пікселях зображення, для кожної клітинки проходимо по чотирьох її сусідах, і якщо сусід білий, викликаємо union_sets.
Таким чином, ми матимемо СНМ з вершинами, що відповідають пікселям зображення.
Отримані дерева в СНМ і будуть шуканими компонентами зв'язності.
Цю задачу також можна розв'язати за допомогою DFS або BFS, але описаний тут метод має перевагу: він може обробляти матрицю рядок за рядком (тобто для обробки рядка нам потрібен лише попередній і поточний рядки, і потрібна лише СНМ, побудована для елементів одного рядка) за пам'яті.
Зберігання додаткової інформації для кожної множини
СНМ дозволяє легко зберігати додаткову інформацію в множинах.
Простим прикладом є розмір множин: зберігання розмірів вже було описано в розділі про об'єднання за розміром (інформація зберігалася в поточного представника множини).
Так само — зберігаючи це у вершинах-представниках — ви можете зберігати й будь-яку іншу інформацію про множини.
Стискання стрибків уздовж відрізка / Зафарбовування підмасивів офлайн
Одним із поширених застосувань СНМ є таке: є множина вершин, і кожна вершина має вихідне ребро до іншої вершини. За допомогою СНМ ви можете знайти кінцеву точку, до якої ми потрапляємо після проходження всіх ребер із заданої початкової точки, майже за сталий час.
Хорошим прикладом цього застосування є задача про зафарбовування підмасивів. Ми маємо відрізок довжиною , кожен елемент початково має колір 0. Нам потрібно перефарбувати підмасив кольором для кожного запиту . Наприкінці ми хочемо знайти підсумковий колір кожної клітинки. Ми припускаємо, що знаємо всі запити заздалегідь, тобто задача офлайн.
Для розв'язку ми можемо зробити СНМ, яка для кожної клітинки зберігає посилання на наступну незафарбовану клітинку. Таким чином, початково кожна клітинка вказує сама на себе. Після виконання одного запитаного перефарбовування відрізка всі клітинки з цього відрізка вказуватимуть на клітинку після відрізка.
Тепер, щоб розв'язати цю задачу, ми розглядаємо запити у зворотному порядку: від останнього до першого. Таким чином, коли ми виконуємо запит, нам потрібно зафарбувати рівно лише незафарбовані клітинки в підмасиві . Усі інші клітинки вже містять свій підсумковий колір. Щоб швидко проходити по всіх незафарбованих клітинках, ми використовуємо СНМ. Ми знаходимо крайню ліву незафарбовану клітинку всередині відрізка, перефарбовуємо її, і за допомогою вказівника переходимо до наступної порожньої клітинки праворуч.
Тут ми можемо використати СНМ зі стисканням шляхів, але не можемо використовувати об'єднання за рангом / розміром (оскільки важливо, хто стане лідером після злиття). Тому складність становитиме на об'єднання (що теж досить швидко).
Реалізація:
- C++
- Python
- TypeScript
- Go
for (int i = 0; i <= L; i++) {
make_set(i);
}
for (int i = m-1; i >= 0; i--) {
int l = query[i].l;
int r = query[i].r;
int c = query[i].c;
for (int v = find_set(l); v <= r; v = find_set(v)) {
answer[v] = c;
parent[v] = v + 1;
}
}
# Потрібен ще один елемент-«страж» за межами відрізка (індекс L+1),
# бо клітинки на правому краю вказуватимуть на v+1.
for i in range(L + 1 + 1):
make_set(i)
for i in range(m - 1, -1, -1):
l, r, c = query[i].l, query[i].r, query[i].c
v = find_set(l)
while v <= r:
answer[v] = c
parent[v] = v + 1
v = find_set(v)
for (let i = 0; i <= L + 1; i++) {
makeSet(i);
}
for (let i = m - 1; i >= 0; i--) {
const { l, r, c } = query[i];
for (let v = findSet(l); v <= r; v = findSet(v)) {
answer[v] = c;
parent[v] = v + 1;
}
}
for i := 0; i <= L+1; i++ {
makeSet(i)
}
for i := m - 1; i >= 0; i-- {
l, r, c := query[i].l, query[i].r, query[i].c
for v := findSet(l); v <= r; v = findSet(v) {
answer[v] = c
parent[v] = v + 1
}
}
Існує оптимізація:
ми можемо використовувати об'єднання за рангом / розміром, якщо зберігаємо наступну незафарбовану клітинку в додатковому масиві end[].
Тоді ми можемо об'єднувати дві множини в одну згідно з їхніми евристиками, і отримуємо розв'язок за .
Підтримка відстаней до представника
Іноді в конкретних застосуваннях СНМ вам потрібно підтримувати відстань між вершиною та представником її множини (тобто довжину шляху в дереві від поточної вершини до кореня дерева).
Якщо ми не використовуємо стискання шляхів, то відстань — це просто кількість рекурсивних викликів. Але це буде неефективно.
Однак можна виконувати стискання шляхів, якщо ми зберігаємо відстань до батька як додаткову інформацію для кожної вершини.
У реалізації зручно використовувати масив пар для parent[], і функція find_set тепер повертає два числа: представника множини та відстань до нього.
- C++
- Python
- TypeScript
- Go
void make_set(int v) {
parent[v] = make_pair(v, 0);
rank[v] = 0;
}
pair<int, int> find_set(int v) {
if (v != parent[v].first) {
int len = parent[v].second;
parent[v] = find_set(parent[v].first);
parent[v].second += len;
}
return parent[v];
}
void union_sets(int a, int b) {
a = find_set(a).first;
b = find_set(b).first;
if (a != b) {
if (rank[a] < rank[b])
swap(a, b);
parent[b] = make_pair(a, 1);
if (rank[a] == rank[b])
rank[a]++;
}
}
# Пару (предок, відстань) зберігаємо як кортеж. Тут стискання шляху лишаємо
# рекурсивним, бо ця версія СНМ використовує об'єднання за рангом —
# висота дерева залишається O(log n), тож межі рекурсії Python вистачає.
def make_set(v):
parent[v] = (v, 0)
rank_[v] = 0
def find_set(v):
if v != parent[v][0]:
length = parent[v][1]
root, dist = find_set(parent[v][0])
parent[v] = (root, dist + length)
return parent[v]
def union_sets(a, b):
a = find_set(a)[0]
b = find_set(b)[0]
if a != b:
if rank_[a] < rank_[b]:
a, b = b, a
parent[b] = (a, 1)
if rank_[a] == rank_[b]:
rank_[a] += 1
// Пару (предок, відстань) зберігаємо як кортеж [number, number].
function makeSet(v: number): void {
parent[v] = [v, 0];
rank[v] = 0;
}
function findSet(v: number): [number, number] {
if (v !== parent[v][0]) {
const len = parent[v][1];
const [root, dist] = findSet(parent[v][0]);
parent[v] = [root, dist + len];
}
return parent[v];
}
function unionSets(a: number, b: number): void {
a = findSet(a)[0];
b = findSet(b)[0];
if (a !== b) {
if (rank[a] < rank[b]) [a, b] = [b, a];
parent[b] = [a, 1];
if (rank[a] === rank[b]) rank[a]++;
}
}
// Пару (предок, відстань) зберігаємо як структуру node{parent, dist}.
type node struct{ parent, dist int }
func makeSet(v int) {
parent[v] = node{v, 0}
rank[v] = 0
}
func findSet(v int) (int, int) {
if v != parent[v].parent {
length := parent[v].dist
root, dist := findSet(parent[v].parent)
parent[v] = node{root, dist + length}
}
return parent[v].parent, parent[v].dist
}
func unionSets(a, b int) {
a, _ = findSet(a)
b, _ = findSet(b)
if a != b {
if rank[a] < rank[b] {
a, b = b, a
}
parent[b] = node{a, 1}
if rank[a] == rank[b] {
rank[a]++
}
}
}
Підтримка парності довжини шляху / Перевірка дводольності онлайн
Так само, як ми обчислюємо довжину шляху до лідера, можна підтримувати парність довжини шляху до нього. Чому це застосування винесено в окремий абзац?
Незвична вимога зберігати парність шляху виникає в такій задачі: спочатку нам дано порожній граф, до нього можна додавати ребра, і нам потрібно відповідати на запити виду «чи є компонента зв'язності, що містить цю вершину, дводольною?».
Щоб розв'язати цю задачу, ми робимо СНМ для зберігання компонент і зберігаємо для кожної вершини парність шляху до представника. Таким чином, ми можемо швидко перевірити, чи призводить додавання ребра до порушення дводольності, чи ні: а саме, якщо кінці ребра лежать в одній компоненті зв'язності та мають однакову парність довжини до лідера, то додавання цього ребра створить цикл непарної довжини, і компонента втратить властивість дводольності.
Єдина складність, з якою ми стикаємося, — це обчислити парність у методі union_find.
Якщо ми додаємо ребро , яке з'єднує дві компоненти зв'язності в одну, то коли ви приєднуєте одне дерево до іншого, нам потрібно скоригувати парність.
Виведемо формулу, яка обчислює парність, що присвоюється лідеру множини, яка приєднається до іншої множини. Нехай — парність довжини шляху від вершини до її лідера , а — парність довжини шляху від вершини до її лідера , і — шукана парність, яку ми маємо присвоїти після злиття. Шлях складається з трьох частин: від до , від до , який з'єднаний одним ребром і тому має парність , і від до . Тому ми отримуємо формулу ( позначає операцію XOR):
Таким чином, незалежно від того, скільки об'єднань ми виконуємо, парність ребер переноситься від одного лідера до іншого.
Наведемо реалізацію СНМ, яка підтримує парність. Як і в попередньому розділі, ми використовуємо пару для зберігання предка та парності. Крім того, для кожної множини ми зберігаємо в масиві bipartite[] те, чи є вона все ще дводольною, чи ні.
- C++
- Python
- TypeScript
- Go
void make_set(int v) {
parent[v] = make_pair(v, 0);
rank[v] = 0;
bipartite[v] = true;
}
pair<int, int> find_set(int v) {
if (v != parent[v].first) {
int parity = parent[v].second;
parent[v] = find_set(parent[v].first);
parent[v].second ^= parity;
}
return parent[v];
}
void add_edge(int a, int b) {
pair<int, int> pa = find_set(a);
a = pa.first;
int x = pa.second;
pair<int, int> pb = find_set(b);
b = pb.first;
int y = pb.second;
if (a == b) {
if (x == y)
bipartite[a] = false;
} else {
if (rank[a] < rank[b])
swap (a, b);
parent[b] = make_pair(a, x^y^1);
bipartite[a] &= bipartite[b];
if (rank[a] == rank[b])
++rank[a];
}
}
bool is_bipartite(int v) {
return bipartite[find_set(v).first];
}
def make_set(v):
parent[v] = (v, 0)
rank_[v] = 0
bipartite[v] = True
def find_set(v):
if v != parent[v][0]:
parity = parent[v][1]
root, par = find_set(parent[v][0])
parent[v] = (root, par ^ parity)
return parent[v]
def add_edge(a, b):
a, x = find_set(a)
b, y = find_set(b)
if a == b:
if x == y:
bipartite[a] = False
else:
if rank_[a] < rank_[b]:
a, b = b, a
parent[b] = (a, x ^ y ^ 1)
bipartite[a] = bipartite[a] and bipartite[b]
if rank_[a] == rank_[b]:
rank_[a] += 1
def is_bipartite(v):
return bipartite[find_set(v)[0]]
function makeSet(v: number): void {
parent[v] = [v, 0];
rank[v] = 0;
bipartite[v] = true;
}
function findSet(v: number): [number, number] {
if (v !== parent[v][0]) {
const parity = parent[v][1];
const [root, par] = findSet(parent[v][0]);
parent[v] = [root, par ^ parity];
}
return parent[v];
}
function addEdge(a: number, b: number): void {
let x: number, y: number;
[a, x] = findSet(a);
[b, y] = findSet(b);
if (a === b) {
if (x === y) bipartite[a] = false;
} else {
if (rank[a] < rank[b]) [a, b] = [b, a];
parent[b] = [a, x ^ y ^ 1];
bipartite[a] = bipartite[a] && bipartite[b];
if (rank[a] === rank[b]) rank[a]++;
}
}
function isBipartite(v: number): boolean {
return bipartite[findSet(v)[0]];
}
type node struct{ parent, parity int }
func makeSet(v int) {
parent[v] = node{v, 0}
rank[v] = 0
bipartite[v] = true
}
func findSet(v int) (int, int) {
if v != parent[v].parent {
parity := parent[v].parity
root, par := findSet(parent[v].parent)
parent[v] = node{root, par ^ parity}
}
return parent[v].parent, parent[v].parity
}
func addEdge(a, b int) {
a, x := findSet(a)
b, y := findSet(b)
if a == b {
if x == y {
bipartite[a] = false
}
} else {
if rank[a] < rank[b] {
a, b = b, a
}
parent[b] = node{a, x ^ y ^ 1}
bipartite[a] = bipartite[a] && bipartite[b]
if rank[a] == rank[b] {
rank[a]++
}
}
}
func isBipartite(v int) bool {
root, _ := findSet(v)
return bipartite[root]
}
Офлайн RMQ (запит мінімуму на відрізку) за у середньому / Трюк Арпи
Нам дано масив a[], і ми маємо обчислити деякі мінімуми на заданих відрізках масиву.
Ідея розв'язку цієї задачі за допомогою СНМ полягає в наступному:
ми проходитимемо по масиву, і коли ми знаходимося на i-му елементі, ми відповідатимемо на всі запити (L, R) з R == i.
Щоб зробити це ефективно, ми підтримуватимемо СНМ, використовуючи перші i елементів, з такою структурою: батьком елемента є наступний менший елемент праворуч від нього.
Тоді, використовуючи цю структуру, відповіддю на запит буде a[find_set(L)] — найменше число праворуч від L.
Цей підхід, очевидно, працює лише офлайн, тобто якщо ми знаємо всі запити заздалегідь.
Легко бачити, що ми можемо застосувати стискання шляхів. А також ми можемо використовувати об'єднання за рангом, якщо зберігаємо справжнього лідера в окремому масиві.
- C++
- Python
- TypeScript
- Go
struct Query {
int L, R, idx;
};
vector<int> answer;
vector<vector<Query>> container;
# Запит зручно зберігати як кортеж (L, R, idx); answer — список,
# container — список списків.
answer = [] # відповіді на запити
container = [] # container[i] — усі запити з R == i
interface Query { L: number; R: number; idx: number; }
let answer: number[] = []; // відповіді на запити
let container: Query[][] = []; // container[i] — усі запити з R == i
type Query struct{ L, R, idx int }
var answer []int // відповіді на запити
var container [][]Query // container[i] — усі запити з R == i
container[i] містить усі запити з R == i.
- C++
- Python
- TypeScript
- Go
stack<int> s;
for (int i = 0; i < n; i++) {
while (!s.empty() && a[s.top()] > a[i]) {
parent[s.top()] = i;
s.pop();
}
s.push(i);
for (Query q : container[i]) {
answer[q.idx] = a[find_set(q.L)];
}
}
# Стек — звичайний список з append/pop.
s = []
for i in range(n):
while s and a[s[-1]] > a[i]:
parent[s.pop()] = i
s.append(i)
for L, R, idx in container[i]:
answer[idx] = a[find_set(L)]
// Стек — масив з push/pop.
const s: number[] = [];
for (let i = 0; i < n; i++) {
while (s.length && a[s[s.length - 1]] > a[i]) parent[s.pop()!] = i;
s.push(i);
for (const q of container[i]) answer[q.idx] = a[findSet(q.L)];
}
// Стек — слайс зі зрізами для pop.
s := []int{}
for i := 0; i < n; i++ {
for len(s) > 0 && a[s[len(s)-1]] > a[i] {
parent[s[len(s)-1]] = i
s = s[:len(s)-1]
}
s = append(s, i)
for _, q := range container[i] {
answer[q.idx] = a[findSet(q.L)]
}
}
Сьогодні цей алгоритм відомий як трюк Арпи. Він названий на честь AmirReza Poorakhavan, який незалежно відкрив і популяризував цю техніку. Хоча цей алгоритм існував ще до його відкриття.
Офлайн LCA (найнижчий спільний предок у дереві) за у середньому
Алгоритм пошуку LCA розглядається в статті Найнижчий спільний предок — офлайн-алгоритм Тар'яна. Цей алгоритм вигідно вирізняється серед інших алгоритмів пошуку LCA своєю простотою (особливо порівняно з оптимальним алгоритмом на кшталт алгоритму Фараха-Колтона та Бендера).
Явне зберігання СНМ у вигляді списку множини / Застосування цієї ідеї при злитті різних структур даних
Одним з альтернативних способів зберігання СНМ є збереження кожної множини у вигляді явно збереженого списку її елементів. При цьому кожен елемент також зберігає посилання на представника своєї множини.
На перший погляд це виглядає як неефективна структура даних: при об'єднанні двох множин нам доведеться додати один список у кінець іншого та оновити лідерство в усіх елементах одного зі списків.
Однак виявляється, що використання вагової евристики (подібної до об'єднання за розміром) може суттєво зменшити асимптотичну складність: для виконання запитів над елементами.
Під ваговою евристикою ми маємо на увазі, що ми завжди додаватимемо меншу з двох множин до більшої множини.
Додавання однієї множини до іншої легко реалізувати в union_sets, і це займе час, пропорційний розміру доданої множини.
А пошук лідера в find_set при такому способі зберігання займе .
Доведемо часову складність для виконання запитів.
Зафіксуємо довільний елемент і підрахуємо, як часто його торкалися в операції злиття union_sets.
Коли елемента торкаються вперше, розмір нової множини буде щонайменше .
Коли його торкаються вдруге, отримана множина матиме розмір щонайменше , оскільки менша множина додається до більшої.
І так далі.
Це означає, що може бути переміщений не більше ніж у операціях злиття.
Таким чином, сума по всіх вершинах дає плюс на кожен запит.
Ось реалізація:
- C++
- Python
- TypeScript
- Go
vector<int> lst[MAXN];
int parent[MAXN];
void make_set(int v) {
lst[v] = vector<int>(1, v);
parent[v] = v;
}
int find_set(int v) {
return parent[v];
}
void union_sets(int a, int b) {
a = find_set(a);
b = find_set(b);
if (a != b) {
if (lst[a].size() < lst[b].size())
swap(a, b);
while (!lst[b].empty()) {
int v = lst[b].back();
lst[b].pop_back();
parent[v] = a;
lst[a].push_back (v);
}
}
}
# lst[v] — список елементів множини; parent[v] — її представник.
def make_set(v):
lst[v] = [v]
parent[v] = v
def find_set(v):
return parent[v]
def union_sets(a, b):
a = find_set(a)
b = find_set(b)
if a != b:
if len(lst[a]) < len(lst[b]):
a, b = b, a
while lst[b]:
v = lst[b].pop()
parent[v] = a
lst[a].append(v)
function makeSet(v: number): void {
lst[v] = [v];
parent[v] = v;
}
function findSet(v: number): number {
return parent[v];
}
function unionSets(a: number, b: number): void {
a = findSet(a);
b = findSet(b);
if (a !== b) {
if (lst[a].length < lst[b].length) [a, b] = [b, a];
while (lst[b].length) {
const v = lst[b].pop()!;
parent[v] = a;
lst[a].push(v);
}
}
}
var lst [MAXN][]int
var parent [MAXN]int
func makeSet(v int) {
lst[v] = []int{v}
parent[v] = v
}
func findSet(v int) int {
return parent[v]
}
func unionSets(a, b int) {
a = findSet(a)
b = findSet(b)
if a != b {
if len(lst[a]) < len(lst[b]) {
a, b = b, a
}
for len(lst[b]) > 0 {
v := lst[b][len(lst[b])-1]
lst[b] = lst[b][:len(lst[b])-1]
parent[v] = a
lst[a] = append(lst[a], v)
}
}
}
Цю ідею додавання меншої частини до більшої можна також використовувати в багатьох розв'язках, які не мають нічого спільного зі СНМ.
Наприклад, розглянемо таку задачу: нам дано дерево, кожному листку призначено число (одне й те саме число може зустрічатися кілька разів на різних листках). Ми хочемо обчислити кількість різних чисел у піддереві для кожної вершини дерева.
Застосовуючи до цієї задачі ту саму ідею, можна отримати такий розв'язок: ми можемо реалізувати DFS, який повертатиме вказівник на множину цілих чисел — список чисел у цьому піддереві. Тоді, щоб отримати відповідь для поточної вершини (якщо, звісно, вона не є листком), ми викликаємо DFS для всіх дітей цієї вершини та об'єднуємо всі отримані множини разом. Розмір отриманої множини і буде відповіддю для поточної вершини. Щоб ефективно поєднати кілька множин, ми просто застосовуємо описаний вище рецепт: ми об'єднуємо множини, просто додаючи менші до більших. У підсумку ми отримуємо розв'язок за , оскільки одне число буде додано до множини не більше ніж разів.
Зберігання СНМ із підтримкою явної деревної структури / Пошук мостів онлайн за у середньому
Одним з найпотужніших застосувань СНМ є те, що вона дозволяє зберігати дерева як у стиснутому, так і в нестиснутому вигляді. Стиснуту форму можна використовувати для злиття дерев та для перевірки, чи знаходяться дві вершини в одному дереві, а нестиснуту форму можна використовувати — наприклад — для пошуку шляхів між двома заданими вершинами або інших обходів деревної структури.
У реалізації це означає, що на додачу до стиснутого масиву предків parent[] нам потрібно буде зберігати масив нестиснутих предків real_parent[].
Очевидно, що підтримка цього додаткового масиву не погіршить складність:
зміни в ньому відбуваються лише тоді, коли ми зливаємо два дерева, і лише в одному елементі.
З іншого боку, при застосуванні на практиці нам часто потрібно з'єднувати дерева за допомогою заданого ребра, а не за допомогою двох кореневих вершин. Це означає, що в нас немає іншого вибору, окрім як перекоренити одне з дерев (зробити кінці ребра новим коренем дерева).
На перший погляд здається, що це перекорінення дуже затратне і сильно погіршить часову складність.
Дійсно, щоб закоренити дерево у вершині , ми маємо пройти від вершини до старого кореня і змінити напрямки в parent[] та real_parent[] для всіх вершин на цьому шляху.
Однак насправді все не так погано: ми можемо просто перекоренити менше з двох дерев, подібно до ідей у попередніх розділах, і отримати у середньому.
Більше деталей (включно з доведенням часової складності) можна знайти в статті Пошук мостів онлайн.
Історичний екскурс
Структура даних СНМ відома вже давно.
Цей спосіб зберігання цієї структури у вигляді лісу дерев був, мабуть, уперше описаний Галлером і Фішером у 1964 році (Galler, Fisher, "An Improved Equivalence Algorithm"), однак повний аналіз часової складності був проведений набагато пізніше.
Оптимізації стискання шляхів та об'єднання за рангом були розроблені Макілроєм і Моррісом, а також незалежно від них Тріттером.
Гопкрофт і Ульман у 1973 році показали часову складність (Hopcroft, Ullman "Set-merging algorithms") — тут — це ітерований логарифм (це повільно зростаюча функція, але все ще не настільки повільна, як обернена функція Аккермана).
Уперше оцінку було показано в 1975 році (Tarjan "Efficiency of a Good But Not Linear Set Union Algorithm"). Пізніше, у 1985 році, він разом із ван Левеном опублікував кілька аналізів складності для кількох різних рангових евристик і способів стискання шляху (Tarjan, Leeuwen "Worst-case Analysis of Set Union Algorithms").
Нарешті, у 1989 році Фредман і Сакс довели, що в прийнятій моделі обчислень будь-який алгоритм для задачі про систему неперетинних множин має працювати щонайменше за часу в середньому (Fredman, Saks, "The cell probe complexity of dynamic data structures").
Задачі
- TIMUS - Anansi's Cobweb
- Codeforces - Roads not only in Berland
- TIMUS - Parity
- SPOJ - Strange Food Chain
- SPOJ - COLORFUL ARRAY
- SPOJ - Consecutive Letters
- Toph - Unbelievable Array
- HackerEarth - Lexicographically minimal string
- HackerEarth - Fight in Ninja World