Решето Ератосфена
Решето Ератосфена — це алгоритм для знаходження всіх простих чисел на відрізку за операцій.
Алгоритм дуже простий: на початку ми виписуємо всі числа від 2 до . Ми позначаємо всі власні кратні числа 2 (оскільки 2 — найменше просте число) як складені. Власне кратне числа — це число, більше за і таке, що ділиться на . Далі ми знаходимо наступне число, яке ще не позначене як складене, у цьому випадку це 3. Це означає, що 3 — просте, і ми позначаємо всі власні кратні числа 3 як складені. Наступне непозначене число — 5, це наступне просте число, і ми позначаємо всі його власні кратні. І ми продовжуємо цю процедуру, доки не опрацюємо всі числа в ряду.
На зображенні нижче ви можете побачити візуалізацію алгоритму для обчислення всіх простих чисел у діапазоні . Можна побачити, що досить часто ми позначаємо числа як складені кілька разів.
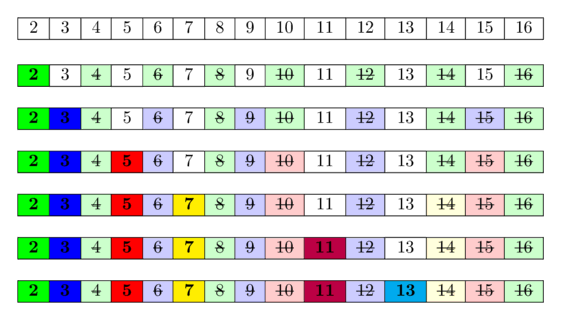
Ідея, що стоїть за цим, така: число є простим, якщо жодне з менших простих чисел його не ділить. Оскільки ми перебираємо прості числа по порядку, ми вже позначили всі числа, які діляться щонайменше на одне з простих чисел, як такі, що діляться. Отже, якщо ми досягаємо клітинки і вона не позначена, то вона не ділиться на жодне менше просте число, а тому має бути простою.
- Чи потрібні всі прості числа (або ознака простоти) на відрізку одразу, а не перевірка окремого числа? (якщо перевіряєте одне велике число → Тести простоти)
- Чи межа вміщується в пам'ять (класичне решето — бітів, орієнтовно до )? Для більших меж — сегментоване решето з цієї ж статті.
- Чи потрібен також найменший простий дільник кожного числа для подальшої факторизації? Тоді розгляньте лінійне решето.
Реалізація
- C++
- Python
- TypeScript
- Go
int n;
vector<bool> is_prime(n+1, true);
is_prime[0] = is_prime[1] = false;
for (int i = 2; i <= n; i++) {
if (is_prime[i] && (long long)i * i <= n) {
for (int j = i * i; j <= n; j += i)
is_prime[j] = false;
}
}
def sieve(n):
# bytearray зберігає 1 байт на елемент і працює дуже швидко
is_prime = bytearray([1]) * (n + 1)
is_prime[0] = is_prime[1] = 0
i = 2
while i <= n:
if is_prime[i] and i * i <= n:
for j in range(i * i, n + 1, i):
is_prime[j] = 0
i += 1
return is_prime
function sieve(n: number): Uint8Array {
// Uint8Array: 1 байт на елемент, швидкий і простий для розуміння
const isPrime = new Uint8Array(n + 1).fill(1);
isPrime[0] = isPrime[1] = 0;
for (let i = 2; i <= n; i++) {
if (isPrime[i] && i * i <= n) {
for (let j = i * i; j <= n; j += i)
isPrime[j] = 0;
}
}
return isPrime;
}
func sieve(n int) []bool {
isPrime := make([]bool, n+1)
for i := range isPrime {
isPrime[i] = true
}
isPrime[0], isPrime[1] = false, false
for i := 2; i <= n; i++ {
if isPrime[i] && i*i <= n {
for j := i * i; j <= n; j += i {
isPrime[j] = false
}
}
}
return isPrime
}
Цей код спочатку позначає всі числа, крім нуля та одиниці, як потенційні прості числа, а потім починає процес просіювання складених чисел.
Для цього він перебирає всі числа від до .
Якщо поточне число є простим, він позначає всі числа, кратні , як складені, починаючи з .
Це вже оптимізація порівняно з наївним способом реалізації, і вона допустима, оскільки всі менші числа, кратні , обов'язково також мають простий множник, менший за , тож усі вони вже були просіяні раніше.
Оскільки легко може переповнити тип int, перед другим вкладеним циклом виконується додаткова перевірка з використанням типу long long.
При такій реалізації алгоритм споживає пам'яті (очевидно) і виконує операцій (див. наступний розділ).
Асимптотичний аналіз
Час роботи легко довести, не знаючи нічого про розподіл простих чисел: якщо знехтувати перевіркою is_prime, внутрішній цикл виконується (щонайбільше) разів для , через що загальна кількість операцій у внутрішньому циклі утворює гармонічну суму на кшталт , яка обмежена .
Доведемо, що час роботи алгоритму становить . Алгоритм виконає операцій у внутрішньому циклі для кожного простого . Отже, нам потрібно оцінити такий вираз:
Згадаймо два відомих факти.
- Кількість простих чисел, менших або рівних , приблизно дорівнює .
- -те просте число приблизно дорівнює (це випливає з попереднього факту).
Таким чином, ми можемо записати суму так:
Тут ми виокремили перше просте число 2 із суми, бо для наближення дорівнює і спричиняє ділення на нуль.
Тепер оцінимо цю суму за допомогою інтеграла тієї самої функції по від до (ми можемо зробити таке наближення, бо насправді сума пов'язана з інтегралом як його наближення методом прямокутників):
Первісною для підінтегральної функції є . Застосувавши заміну та відкинувши члени нижчого порядку, отримаємо результат:
Тепер, повертаючись до початкової суми, отримаємо її приблизну оцінку:
Суворіше доведення (яке дає точнішу оцінку з точністю до сталих множників) можна знайти в книзі Hardy & Wright «An Introduction to the Theory of Numbers» (с. 349).
Різні оптимізації решета Ератосфена
Найбільша слабкість алгоритму в тому, що він «прогулюється» по пам'яті кілька разів, маніпулюючи лише окремими елементами. Це не дуже дружнє до кешу. І через це стала, прихована в , є порівняно великою.
Окрім того, спожита пам'ять є вузьким місцем для великих .
Наведені нижче методи дозволяють нам зменшити кількість виконуваних операцій, а також помітно скоротити спожиту пам'ять.
Просіювання до кореня
Очевидно, щоб знайти всі прості числа до , достатньо виконати просіювання лише за простими числами, які не перевищують кореня з .
- C++
- Python
- TypeScript
- Go
int n;
vector<bool> is_prime(n+1, true);
is_prime[0] = is_prime[1] = false;
for (int i = 2; i * i <= n; i++) {
if (is_prime[i]) {
for (int j = i * i; j <= n; j += i)
is_prime[j] = false;
}
}
def sieve(n):
# просіюємо лише за простими до кореня з n
is_prime = bytearray([1]) * (n + 1)
is_prime[0] = is_prime[1] = 0
i = 2
while i * i <= n:
if is_prime[i]:
for j in range(i * i, n + 1, i):
is_prime[j] = 0
i += 1
return is_prime
function sieve(n: number): Uint8Array {
// просіюємо лише за простими до кореня з n
const isPrime = new Uint8Array(n + 1).fill(1);
isPrime[0] = isPrime[1] = 0;
for (let i = 2; i * i <= n; i++) {
if (isPrime[i]) {
for (let j = i * i; j <= n; j += i)
isPrime[j] = 0;
}
}
return isPrime;
}
func sieve(n int) []bool {
isPrime := make([]bool, n+1)
for i := range isPrime {
isPrime[i] = true
}
isPrime[0], isPrime[1] = false, false
// просіюємо лише за простими до кореня з n
for i := 2; i*i <= n; i++ {
if isPrime[i] {
for j := i * i; j <= n; j += i {
isPrime[j] = false
}
}
}
return isPrime
}
Така оптимізація не впливає на складність (справді, повторивши наведене вище доведення, отримаємо оцінку , яка асимптотично така сама за властивостями логарифмів), хоча кількість операцій помітно зменшиться.
Просіювання лише за непарними числами
Оскільки всі парні числа (крім ) складені, ми можемо взагалі припинити перевірку парних чисел. Натомість нам потрібно оперувати лише непарними числами.
По-перше, це дозволить нам удвічі зменшити потрібну пам'ять. По-друге, це приблизно вдвічі скоротить кількість операцій, виконуваних алгоритмом.
Споживання пам'яті та швидкість операцій
Слід зауважити, що ці дві реалізації решета Ератосфена використовують бітів пам'яті за допомогою структури даних vector<bool>.
vector<bool> — це не звичайний контейнер, що зберігає послідовність значень bool (бо в більшості комп'ютерних архітектур bool займає один байт пам'яті).
Це спеціалізація vector<T>, оптимізована за пам'яттю, яка споживає лише байтів пам'яті.
Сучасні архітектури процесорів працюють набагато ефективніше з байтами, ніж з бітами, оскільки зазвичай не можуть звертатися до бітів безпосередньо.
Тож «під капотом» vector<bool> зберігає біти у великому неперервному блоці пам'яті, звертається до пам'яті блоками по кілька байтів і витягує/встановлює біти за допомогою бітових операцій, таких як бітові маски та бітові зсуви.
Через це є певні накладні витрати, коли ви читаєте чи записуєте біти у vector<bool>, і досить часто використання vector<char> (який використовує 1 байт на кожен запис, тобто у 8 разів більше пам'яті) є швидшим.
Однак для простих реалізацій решета Ератосфена використання vector<bool> є швидшим.
Ви обмежені тим, наскільки швидко можете завантажити дані в кеш, а тому використання меншого обсягу пам'яті дає велику перевагу.
Замір швидкодії (посилання) показує, що використання vector<bool> у 1.4–1.7 раза швидше, ніж використання vector<char>.
Ті самі міркування стосуються й bitset.
Це теж ефективний спосіб зберігання бітів, подібний до vector<bool>, тож він займає лише байтів пам'яті, але дещо повільніший у доступі до елементів.
У наведеному вище замірі bitset показує себе трохи гірше за vector<bool>.
Ще один недолік bitset полягає в тому, що його розмір потрібно знати на етапі компіляції.
Блочне решето
З оптимізації «просіювання до кореня» випливає, що немає потреби постійно тримати весь масив is_prime[1...n].
Для просіювання достатньо тримати лише прості числа до кореня з , тобто prime[1... sqrt(n)], розбити весь діапазон на блоки та просіювати кожен блок окремо.
Нехай — стала, яка визначає розмір блоку, тоді всього в нас блоків, і блок () містить числа з відрізка . Ми можемо опрацьовувати блоки по черзі, тобто для кожного блоку ми пройдемо по всіх простих числах (від до ) і виконаємо просіювання за їх допомогою. Варто зауважити, що нам доведеться трохи змінити стратегію при опрацюванні перших чисел: по-перше, усі прості числа з не повинні викреслювати самі себе; і по-друге, числа та слід позначити як непрості. Працюючи з останнім блоком, не слід забувати, що останнє потрібне число не обов'язково розташоване в кінці блоку.
Як обговорювалося раніше, типова реалізація решета Ератосфена обмежена тим, наскільки швидко можна завантажувати дані в кеші процесора.
Розбиваючи діапазон потенційних простих чисел на менші блоки, нам ніколи не доводиться тримати кілька блоків у пам'яті одночасно, і всі операції стають значно дружнішими до кешу.
Оскільки тепер ми більше не обмежені швидкістю кешу, ми можемо замінити vector<bool> на vector<char> і отримати додаткову продуктивність, бо процесори можуть напряму обробляти читання та записи байтів і не мусять покладатися на бітові операції для витягування окремих бітів.
Замір швидкодії (посилання) показує, що використання vector<char> у цій ситуації приблизно у 3 рази швидше, ніж використання vector<bool>.
Слово застереження: ці числа можуть відрізнятися залежно від архітектури, компілятора та рівнів оптимізації.
Нижче наведено реалізацію, яка підраховує кількість простих чисел, менших або рівних , за допомогою блочного просіювання.
- C++
- Python
- TypeScript
- Go
int count_primes(int n) {
const int S = 10000;
vector<int> primes;
int nsqrt = sqrt(n);
vector<char> is_prime(nsqrt + 2, true);
for (int i = 2; i <= nsqrt; i++) {
if (is_prime[i]) {
primes.push_back(i);
for (int j = i * i; j <= nsqrt; j += i)
is_prime[j] = false;
}
}
int result = 0;
vector<char> block(S);
for (int k = 0; k * S <= n; k++) {
fill(block.begin(), block.end(), true);
int start = k * S;
for (int p : primes) {
int start_idx = (start + p - 1) / p;
int j = max(start_idx, p) * p - start;
for (; j < S; j += p)
block[j] = false;
}
if (k == 0)
block[0] = block[1] = false;
for (int i = 0; i < S && start + i <= n; i++) {
if (block[i])
result++;
}
}
return result;
}
def count_primes(n):
S = 10000
primes = []
nsqrt = int(n ** 0.5)
is_prime = bytearray([1]) * (nsqrt + 2)
for i in range(2, nsqrt + 1):
if is_prime[i]:
primes.append(i)
for j in range(i * i, nsqrt + 1, i):
is_prime[j] = 0
result = 0
k = 0
while k * S <= n:
block = bytearray([1]) * S # для кожного блоку заново позначаємо всі як прості
start = k * S
for p in primes:
start_idx = (start + p - 1) // p
j = max(start_idx, p) * p - start
while j < S:
block[j] = 0
j += p
if k == 0:
block[0] = block[1] = 0
i = 0
while i < S and start + i <= n:
if block[i]:
result += 1
i += 1
k += 1
return result
function countPrimes(n: number): number {
const S = 10000;
const primes: number[] = [];
const nsqrt = Math.floor(Math.sqrt(n));
const isPrime = new Uint8Array(nsqrt + 2).fill(1);
for (let i = 2; i <= nsqrt; i++) {
if (isPrime[i]) {
primes.push(i);
for (let j = i * i; j <= nsqrt; j += i)
isPrime[j] = 0;
}
}
let result = 0;
const block = new Uint8Array(S);
for (let k = 0; k * S <= n; k++) {
block.fill(1); // для кожного блоку заново позначаємо всі як прості
const start = k * S;
for (const p of primes) {
const startIdx = Math.floor((start + p - 1) / p);
let j = Math.max(startIdx, p) * p - start;
for (; j < S; j += p)
block[j] = 0;
}
if (k === 0)
block[0] = block[1] = 0;
for (let i = 0; i < S && start + i <= n; i++) {
if (block[i])
result++;
}
}
return result;
}
func countPrimes(n int) int {
const S = 10000
var primes []int
nsqrt := int(math.Sqrt(float64(n)))
isPrime := make([]bool, nsqrt+2)
for i := range isPrime {
isPrime[i] = true
}
for i := 2; i <= nsqrt; i++ {
if isPrime[i] {
primes = append(primes, i)
for j := i * i; j <= nsqrt; j += i {
isPrime[j] = false
}
}
}
result := 0
block := make([]bool, S)
for k := 0; k*S <= n; k++ {
for i := range block { // для кожного блоку заново позначаємо всі як прості
block[i] = true
}
start := k * S
for _, p := range primes {
startIdx := (start + p - 1) / p
j := max(startIdx, p)*p - start
for ; j < S; j += p {
block[j] = false
}
}
if k == 0 {
block[0], block[1] = false, false
}
for i := 0; i < S && start+i <= n; i++ {
if block[i] {
result++
}
}
}
return result
}
Час роботи блочного просіювання такий самий, як у звичайного решета Ератосфена (якщо розмір блоків не дуже малий), але потрібна пам'ять скоротиться до , і ми отримаємо кращі результати кешування. З іншого боку, на кожну пару «блок — просте число з » припадатиме одне ділення, і це буде набагато гірше для менших розмірів блоків. Отже, при виборі сталої необхідно дотримуватися балансу. Найкращих результатів ми досягли для розмірів блоків між та .
Знаходження простих чисел на відрізку
Іноді нам потрібно знайти всі прості числа на відрізку малого розміру (наприклад, ), де може бути дуже великим (наприклад, ).
Щоб розв'язати таку задачу, ми можемо скористатися ідеєю блочного решета. Ми заздалегідь генеруємо всі прості числа до і використовуємо ці прості числа, щоб позначити всі складені числа на відрізку .
- C++
- Python
- TypeScript
- Go
vector<char> segmentedSieve(long long L, long long R) {
// генеруємо всі прості числа до sqrt(R)
long long lim = sqrt(R);
vector<char> mark(lim + 1, false);
vector<long long> primes;
for (long long i = 2; i <= lim; ++i) {
if (!mark[i]) {
primes.emplace_back(i);
for (long long j = i * i; j <= lim; j += i)
mark[j] = true;
}
}
vector<char> isPrime(R - L + 1, true);
for (long long i : primes)
for (long long j = max(i * i, (L + i - 1) / i * i); j <= R; j += i)
isPrime[j - L] = false;
if (L == 1)
isPrime[0] = false;
return isPrime;
}
def segmented_sieve(L, R):
# генеруємо всі прості числа до sqrt(R)
lim = int(R ** 0.5)
mark = bytearray(lim + 1) # 0 = просте, 1 = складене
primes = []
for i in range(2, lim + 1):
if not mark[i]:
primes.append(i)
for j in range(i * i, lim + 1, i):
mark[j] = 1
is_prime = bytearray([1]) * (R - L + 1)
for i in primes:
for j in range(max(i * i, (L + i - 1) // i * i), R + 1, i):
is_prime[j - L] = 0
if L == 1:
is_prime[0] = 0
return is_prime
// Для дуже великих R слід перейти на bigint; number вистачає для R <= 2^53
function segmentedSieve(L: number, R: number): Uint8Array {
// генеруємо всі прості числа до sqrt(R)
const lim = Math.floor(Math.sqrt(R));
const mark = new Uint8Array(lim + 1); // 0 = просте, 1 = складене
const primes: number[] = [];
for (let i = 2; i <= lim; i++) {
if (!mark[i]) {
primes.push(i);
for (let j = i * i; j <= lim; j += i)
mark[j] = 1;
}
}
const isPrime = new Uint8Array(R - L + 1).fill(1);
for (const i of primes)
for (let j = Math.max(i * i, Math.floor((L + i - 1) / i) * i); j <= R; j += i)
isPrime[j - L] = 0;
if (L === 1)
isPrime[0] = 0;
return isPrime;
}
func segmentedSieve(L, R int64) []bool {
// генеруємо всі прості числа до sqrt(R)
lim := int64(math.Sqrt(float64(R)))
mark := make([]bool, lim+1) // false = просте, true = складене
var primes []int64
for i := int64(2); i <= lim; i++ {
if !mark[i] {
primes = append(primes, i)
for j := i * i; j <= lim; j += i {
mark[j] = true
}
}
}
isPrime := make([]bool, R-L+1)
for i := range isPrime {
isPrime[i] = true
}
for _, i := range primes {
for j := max(i*i, (L+i-1)/i*i); j <= R; j += i {
isPrime[j-L] = false
}
}
if L == 1 {
isPrime[0] = false
}
return isPrime
}
Часова складність цього підходу становить .
Також можливо обійтися без попередньої генерації всіх простих чисел:
- C++
- Python
- TypeScript
- Go
vector<char> segmentedSieveNoPreGen(long long L, long long R) {
vector<char> isPrime(R - L + 1, true);
long long lim = sqrt(R);
for (long long i = 2; i <= lim; ++i)
for (long long j = max(i * i, (L + i - 1) / i * i); j <= R; j += i)
isPrime[j - L] = false;
if (L == 1)
isPrime[0] = false;
return isPrime;
}
def segmented_sieve_no_pregen(L, R):
is_prime = bytearray([1]) * (R - L + 1)
lim = int(R ** 0.5)
for i in range(2, lim + 1):
for j in range(max(i * i, (L + i - 1) // i * i), R + 1, i):
is_prime[j - L] = 0
if L == 1:
is_prime[0] = 0
return is_prime
function segmentedSieveNoPreGen(L: number, R: number): Uint8Array {
const isPrime = new Uint8Array(R - L + 1).fill(1);
const lim = Math.floor(Math.sqrt(R));
for (let i = 2; i <= lim; i++)
for (let j = Math.max(i * i, Math.floor((L + i - 1) / i) * i); j <= R; j += i)
isPrime[j - L] = 0;
if (L === 1)
isPrime[0] = 0;
return isPrime;
}
func segmentedSieveNoPreGen(L, R int64) []bool {
isPrime := make([]bool, R-L+1)
for i := range isPrime {
isPrime[i] = true
}
lim := int64(math.Sqrt(float64(R)))
for i := int64(2); i <= lim; i++ {
for j := max(i*i, (L+i-1)/i*i); j <= R; j += i {
isPrime[j-L] = false
}
}
if L == 1 {
isPrime[0] = false
}
return isPrime
}
Очевидно, складність гірша й становить . Проте на практиці це все одно працює дуже швидко.
Модифікація з лінійним часом роботи
Ми можемо модифікувати алгоритм у такий спосіб, щоб він мав лише лінійну часову складність. Цей підхід описано в статті Лінійне решето. Однак цей алгоритм також має свої слабкі сторони.
Задачі для практики
- Leetcode - Four Divisors
- Leetcode - Count Primes
- SPOJ - Printing Some Primes
- SPOJ - A Conjecture of Paul Erdos
- SPOJ - Primal Fear
- SPOJ - Primes Triangle (I)
- Codeforces - Almost Prime
- Codeforces - Sherlock And His Girlfriend
- SPOJ - Namit in Trouble
- SPOJ - Bazinga!
- Project Euler - Prime pair connection
- SPOJ - N-Factorful
- SPOJ - Binary Sequence of Prime Numbers
- UVA 11353 - A Different Kind of Sorting
- SPOJ - Prime Generator
- SPOJ - Printing some primes (hard)
- Codeforces - Nodbach Problem
- Codeforces - Colliders