Факторизація цілих чисел
У цій статті ми розглянемо кілька алгоритмів факторизації цілих чисел, кожен з яких може бути або швидким, або повільним різною мірою залежно від вхідних даних.
Зауважимо: якщо число, яке ви хочете розкласти на множники, насправді є простим, більшість алгоритмів працюватимуть дуже повільно. Особливо це стосується методу Ферма, методу Полларда p−1 та ро-алгоритму Полларда. Тому має сенс спершу виконати ймовірнісний (або швидкий детермінований) тест на простоту, перш ніж намагатися розкласти число на множники.
- Чи потрібно знайти прості множники одного (чи кількох) великих чисел? (якщо потрібно лише перевірити, просте число чи ні → Тести простоти)
- Якщо — чи влаштовує просте пробне ділення за , а для більших чисел потрібен ро-алгоритм Полларда за ?
- Якщо потрібні розклади всіх чисел від до — (→ Лінійне решето чи Решето Ератосфена)?
Пробне ділення
Це найбазовіший алгоритм для пошуку розкладу на прості множники.
Ми ділимо число на кожен можливий дільник . Можна помітити, що неможливо, щоб усі прості множники складеного числа були більшими за . Тому нам достатньо перевірити лише дільники , що дає нам розклад на прості множники за . (Це псевдополіноміальний час, тобто поліноміальний відносно значення входу, але експоненційний відносно кількості бітів входу.)
Найменший дільник обов'язково є простим числом. Ми прибираємо знайдений множник і продовжуємо процес. Якщо ми не можемо знайти жодного дільника в діапазоні , то саме число має бути простим.
- C++
- Python
- TypeScript
- Go
vector<long long> trial_division1(long long n) {
vector<long long> factorization;
for (long long d = 2; d * d <= n; d++) {
while (n % d == 0) {
factorization.push_back(d);
n /= d;
}
}
if (n > 1)
factorization.push_back(n);
return factorization;
}
def trial_division1(n: int) -> list[int]:
factorization: list[int] = []
d = 2
while d * d <= n:
while n % d == 0: # виносимо множник d стільки разів, скільки можемо
factorization.append(d)
n //= d
d += 1
if n > 1: # залишок — це простий множник
factorization.append(n)
return factorization
// для n у межах Number.MAX_SAFE_INTEGER (< 2^53)
function trialDivision1(n: number): number[] {
const factorization: number[] = [];
for (let d = 2; d * d <= n; d++) {
while (n % d === 0) { // виносимо множник d стільки разів, скільки можемо
factorization.push(d);
n /= d;
}
}
if (n > 1) factorization.push(n); // залишок — це простий множник
return factorization;
}
func trialDivision1(n int64) []int64 {
var factorization []int64
for d := int64(2); d*d <= n; d++ {
for n%d == 0 { // виносимо множник d стільки разів, скільки можемо
factorization = append(factorization, d)
n /= d
}
}
if n > 1 { // залишок — це простий множник
factorization = append(factorization, n)
}
return factorization
}
Факторизація з колесом
Це оптимізація пробного ділення. Коли ми вже знаємо, що число не ділиться на 2, нам не потрібно перевіряти інші парні числа. Це залишає нам лише чисел для перевірки. Після того як ми винесли 2 й отримали непарне число, ми можемо просто почати з 3 і враховувати лише інші непарні числа.
- C++
- Python
- TypeScript
- Go
vector<long long> trial_division2(long long n) {
vector<long long> factorization;
while (n % 2 == 0) {
factorization.push_back(2);
n /= 2;
}
for (long long d = 3; d * d <= n; d += 2) {
while (n % d == 0) {
factorization.push_back(d);
n /= d;
}
}
if (n > 1)
factorization.push_back(n);
return factorization;
}
def trial_division2(n: int) -> list[int]:
factorization: list[int] = []
while n % 2 == 0: # спершу виносимо всі двійки
factorization.append(2)
n //= 2
d = 3
while d * d <= n: # далі перевіряємо лише непарні дільники
while n % d == 0:
factorization.append(d)
n //= d
d += 2
if n > 1:
factorization.append(n)
return factorization
function trialDivision2(n: number): number[] {
const factorization: number[] = [];
while (n % 2 === 0) { // спершу виносимо всі двійки
factorization.push(2);
n /= 2;
}
for (let d = 3; d * d <= n; d += 2) { // далі лише непарні дільники
while (n % d === 0) {
factorization.push(d);
n /= d;
}
}
if (n > 1) factorization.push(n);
return factorization;
}
func trialDivision2(n int64) []int64 {
var factorization []int64
for n%2 == 0 { // спершу виносимо всі двійки
factorization = append(factorization, 2)
n /= 2
}
for d := int64(3); d*d <= n; d += 2 { // далі лише непарні дільники
for n%d == 0 {
factorization = append(factorization, d)
n /= d
}
}
if n > 1 {
factorization = append(factorization, n)
}
return factorization
}
Цей метод можна розширити далі. Якщо число не ділиться на 3, ми також можемо ігнорувати всі інші кратні 3 в подальших обчисленнях. Отже, нам потрібно перевіряти лише числа . Ми можемо помітити закономірність у цих числах, що залишилися. Нам потрібно перевіряти всі числа з та . Отже, це залишає нам лише відсотків чисел для перевірки. Ми можемо це реалізувати, спершу винісши прості множники 2 і 3, після чого починаємо з 5 і враховуємо лише остачі та за модулем .
Ось реалізація для простих чисел 2, 3 і 5. Зручно зберігати кроки пропуску в масиві.
- C++
- Python
- TypeScript
- Go
vector<long long> trial_division3(long long n) {
vector<long long> factorization;
for (int d : {2, 3, 5}) {
while (n % d == 0) {
factorization.push_back(d);
n /= d;
}
}
static array<int, 8> increments = {4, 2, 4, 2, 4, 6, 2, 6};
int i = 0;
for (long long d = 7; d * d <= n; d += increments[i++]) {
while (n % d == 0) {
factorization.push_back(d);
n /= d;
}
if (i == 8)
i = 0;
}
if (n > 1)
factorization.push_back(n);
return factorization;
}
def trial_division3(n: int) -> list[int]:
factorization: list[int] = []
for d in (2, 3, 5): # виносимо прості з колеса 2*3*5
while n % d == 0:
factorization.append(d)
n //= d
increments = (4, 2, 4, 2, 4, 6, 2, 6) # кроки колеса по модулю 30
i = 0
d = 7
while d * d <= n:
while n % d == 0:
factorization.append(d)
n //= d
d += increments[i]
i += 1
if i == 8:
i = 0
if n > 1:
factorization.append(n)
return factorization
function trialDivision3(n: number): number[] {
const factorization: number[] = [];
for (const d of [2, 3, 5]) { // виносимо прості з колеса 2*3*5
while (n % d === 0) {
factorization.push(d);
n /= d;
}
}
const increments = [4, 2, 4, 2, 4, 6, 2, 6]; // кроки колеса по модулю 30
let i = 0;
for (let d = 7; d * d <= n; d += increments[i++]) {
while (n % d === 0) {
factorization.push(d);
n /= d;
}
if (i === 8) i = 0;
}
if (n > 1) factorization.push(n);
return factorization;
}
func trialDivision3(n int64) []int64 {
var factorization []int64
for _, d := range []int64{2, 3, 5} { // виносимо прості з колеса 2*3*5
for n%d == 0 {
factorization = append(factorization, d)
n /= d
}
}
increments := [8]int64{4, 2, 4, 2, 4, 6, 2, 6} // кроки колеса по модулю 30
i := 0
for d := int64(7); d*d <= n; {
for n%d == 0 {
factorization = append(factorization, d)
n /= d
}
d += increments[i]
i++
if i == 8 {
i = 0
}
}
if n > 1 {
factorization = append(factorization, n)
}
return factorization
}
Якщо ми продовжимо розширювати цей метод, додаючи ще більше простих чисел, можна досягти кращих відсотків, але списки пропусків ставатимуть більшими.
Попередньо обчислені прості числа
Розширюючи метод факторизації з колесом нескінченно, ми зрештою залишимося лише з простими числами для перевірки. Хороший спосіб це зробити — попередньо обчислити всі прості числа за допомогою решета Ератосфена до і перевіряти їх по черзі.
- C++
- Python
- TypeScript
- Go
vector<long long> primes;
vector<long long> trial_division4(long long n) {
vector<long long> factorization;
for (long long d : primes) {
if (d * d > n)
break;
while (n % d == 0) {
factorization.push_back(d);
n /= d;
}
}
if (n > 1)
factorization.push_back(n);
return factorization;
}
# primes — список заздалегідь обчислених простих (наприклад, решетом Ератосфена)
primes: list[int] = []
def trial_division4(n: int) -> list[int]:
factorization: list[int] = []
for d in primes:
if d * d > n:
break
while n % d == 0:
factorization.append(d)
n //= d
if n > 1:
factorization.append(n)
return factorization
// primes — масив заздалегідь обчислених простих (наприклад, решетом Ератосфена)
const primes: number[] = [];
function trialDivision4(n: number): number[] {
const factorization: number[] = [];
for (const d of primes) {
if (d * d > n) break;
while (n % d === 0) {
factorization.push(d);
n /= d;
}
}
if (n > 1) factorization.push(n);
return factorization;
}
// primes — зріз заздалегідь обчислених простих (наприклад, решетом Ератосфена)
var primes []int64
func trialDivision4(n int64) []int64 {
var factorization []int64
for _, d := range primes {
if d*d > n {
break
}
for n%d == 0 {
factorization = append(factorization, d)
n /= d
}
}
if n > 1 {
factorization = append(factorization, n)
}
return factorization
}
Метод факторизації Ферма
Ми можемо записати непарне складене число як різницю двох квадратів :
Метод факторизації Ферма намагається використати цей факт, вгадуючи перший квадрат і перевіряючи, чи є квадратом і друга частина, . Якщо так, то ми знайшли множники та числа .
- C++
- Python
- TypeScript
- Go
int fermat(int n) {
int a = ceil(sqrt(n));
int b2 = a*a - n;
int b = round(sqrt(b2));
while (b * b != b2) {
a = a + 1;
b2 = a*a - n;
b = round(sqrt(b2));
}
return a - b;
}
from math import isqrt
def fermat(n: int) -> int:
a = isqrt(n)
if a * a < n: # ceil(sqrt(n)) через цілий корінь — без похибок float
a += 1
b2 = a * a - n
b = isqrt(b2)
while b * b != b2: # шукаємо a, для якого a^2 - n є точним квадратом
a += 1
b2 = a * a - n
b = isqrt(b2)
return a - b
function fermat(n: number): number {
let a = Math.ceil(Math.sqrt(n));
let b2 = a * a - n;
let b = Math.round(Math.sqrt(b2));
while (b * b !== b2) { // шукаємо a, для якого a^2 - n є точним квадратом
a += 1;
b2 = a * a - n;
b = Math.round(Math.sqrt(b2));
}
return a - b;
}
func fermat(n int64) int64 {
a := int64(math.Ceil(math.Sqrt(float64(n))))
b2 := a*a - n
b := int64(math.Round(math.Sqrt(float64(b2))))
for b*b != b2 { // шукаємо a, для якого a^2 - n є точним квадратом
a++
b2 = a*a - n
b = int64(math.Round(math.Sqrt(float64(b2))))
}
return a - b
}
Цей метод факторизації може бути дуже швидким, якщо різниця між двома множниками та мала. Алгоритм працює за час . Проте на практиці цей метод використовують рідко. Щойно множники віддаляються один від одного, він стає вкрай повільним.
Однак щодо цього підходу все ще існує велика кількість варіантів оптимізації. Розглядаючи квадрати за модулем фіксованого малого числа, можна помітити, що певні значення не потрібно розглядати, оскільки вони не можуть дати квадрат .
Метод Полларда
Дуже ймовірно, що число має принаймні один простий множник такий, що є -степенево-гладким для малого . Кажуть, що ціле число є -степенево-гладким, якщо кожен простий степінь, що ділить , не перевищує . Формально, нехай і нехай — довільне додатне ціле число. Припустимо, що розклад на прості множники є , де кожне — просте число, а . Тоді є -степенево-гладким, якщо для всіх виконується . Наприклад, розклад числа на прості множники — це . А значення та є відповідно -степенево-гладким і -степенево-гладким, оскільки та . У 1974 році Джон Поллард винайшов метод для виділення зі складеного числа множників таких, що є -степенево-гладким.
Ідея походить із малої теореми Ферма. Нехай розклад буде . Вона стверджує, що якщо взаємно просте з , то виконується таке твердження:
Це також означає, що
Отже, для будь-якого з ми знаємо, що . Це означає, що , а через це також .
Тому, якщо для множника числа ділить , ми можемо виділити множник за допомогою алгоритму Евкліда.
Зрозуміло, що найменше , яке є кратним кожному -степенево-гладкому числу, — це . Або, як альтернатива:
Зауважимо: якщо ділить для всіх простих множників числа , то просто дорівнюватиме . У цьому випадку ми не отримуємо множника. Тому ми намагатимемося виконувати кілька разів, поки обчислюємо .
Деякі складені числа не мають множників таких, що є -степенево-гладким для малого . Наприклад, для складеного числа значення є відповідно -степенево-гладким і -степенево-гладким. Нам доведеться обрати , щоб розкласти це число на множники.
У наведеній нижче реалізації ми починаємо з і збільшуємо після кожної ітерації.
- C++
- Python
- TypeScript
- Go
long long pollards_p_minus_1(long long n) {
int B = 10;
long long g = 1;
while (B <= 1000000 && g < n) {
long long a = 2 + rand() % (n - 3);
g = gcd(a, n);
if (g > 1)
return g;
// обчислюємо a^M
for (int p : primes) {
if (p >= B)
continue;
long long p_power = 1;
while (p_power * p <= B)
p_power *= p;
a = power(a, p_power, n);
g = gcd(a - 1, n);
if (g > 1 && g < n)
return g;
}
B *= 2;
}
return 1;
}
import random
from math import gcd
# primes — список заздалегідь обчислених простих
# Python оперує великими числами нативно, тож переповнення немає,
# а вбудований pow(a, e, n) — це швидке модулярне піднесення до степеня.
def pollards_p_minus_1(n: int) -> int:
B = 10
g = 1
while B <= 1_000_000 and g < n:
a = 2 + random.randint(0, n - 4) # випадкове a з [2, n-2]
g = gcd(a, n)
if g > 1:
return g
# обчислюємо a^M
for p in primes:
if p >= B:
continue
p_power = 1
while p_power * p <= B:
p_power *= p
a = pow(a, p_power, n)
g = gcd(a - 1, n)
if 1 < g < n:
return g
B *= 2
return 1
// bigint обов'язковий: a^M mod n переповнює звичайний number (> 2^53)
const primes: bigint[] = []; // заздалегідь обчислені прості
function gcd(a: bigint, b: bigint): bigint {
while (b) [a, b] = [b, a % b];
return a < 0n ? -a : a;
}
function powMod(a: bigint, e: bigint, mod: bigint): bigint {
let res = 1n;
a %= mod;
while (e > 0n) {
if (e & 1n) res = (res * a) % mod;
a = (a * a) % mod;
e >>= 1n;
}
return res;
}
function pollardsPMinus1(n: bigint): bigint {
let B = 10n;
let g = 1n;
while (B <= 1_000_000n && g < n) {
// випадкове a з [2, n-2]
const a0 = 2n + BigInt(Math.floor(Math.random() * 1e15)) % (n - 3n);
let a = a0;
g = gcd(a, n);
if (g > 1n) return g;
// обчислюємо a^M
for (const p of primes) {
if (p >= B) continue;
let pPower = 1n;
while (pPower * p <= B) pPower *= p;
a = powMod(a, pPower, n);
g = gcd(a - 1n, n);
if (g > 1n && g < n) return g;
}
B *= 2n;
}
return 1n;
}
import (
"math/big"
"math/rand"
)
// При n до 1e18 множення a*a переповнює uint64, тому беремо math/big.
// (як альтернатива — mulmod через math/bits.Mul64 + ділення, але це складніше.)
var primes []int64 // заздалегідь обчислені прості
func pollardsPMinus1(n *big.Int) *big.Int {
B := int64(10)
g := big.NewInt(1)
one := big.NewInt(1)
for B <= 1_000_000 && g.Cmp(n) < 0 {
// випадкове a з [2, n-2]
r := new(big.Int).Rand(rand.New(rand.NewSource(1)), new(big.Int).Sub(n, big.NewInt(3)))
a := new(big.Int).Add(r, big.NewInt(2))
g = new(big.Int).GCD(nil, nil, a, n)
if g.Cmp(one) > 0 {
return g
}
// обчислюємо a^M
for _, p := range primes {
if p >= B {
continue
}
pPower := int64(1)
for pPower*p <= B {
pPower *= p
}
a.Exp(a, big.NewInt(pPower), n) // швидке модулярне піднесення до степеня
g = new(big.Int).GCD(nil, nil, new(big.Int).Sub(a, one), n)
if g.Cmp(one) > 0 && g.Cmp(n) < 0 {
return g
}
}
B *= 2
}
return big.NewInt(1)
}
Зауважте, що це ймовірнісний алгоритм. Наслідком цього є те, що існує можливість того, що алгоритм узагалі не зможе знайти множник.
Складність становить на одну ітерацію.
Ро-алгоритм Полларда
Ро-алгоритм Полларда — це ще один алгоритм факторизації від Джона Полларда.
Нехай розклад числа на прості множники буде . Алгоритм розглядає псевдовипадкову послідовність , де — поліноміальна функція; зазвичай обирають з .
У цьому випадку нас цікавить не сама послідовність . Нас більше цікавить послідовність . Оскільки — поліноміальна функція, а всі значення лежать у діапазоні , ця послідовність зрештою зійдеться в цикл. Парадокс днів народження насправді підказує, що очікувана кількість елементів до початку повторення становить . Якщо менше за , повторення, ймовірно, почнеться за .
Ось візуалізація такої послідовності з , , та . З форми послідовності ви можете дуже чітко побачити, чому алгоритм названо ро-алгоритмом Полларда ().
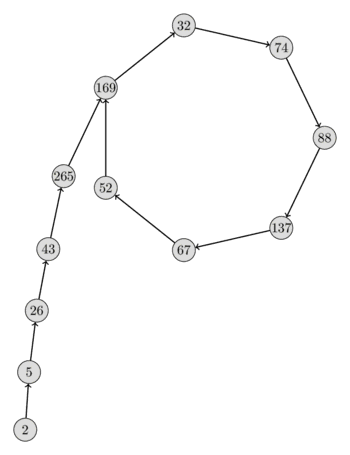
Проте все ще залишається відкрите питання. Як ми можемо скористатися властивостями послідовності на свою користь, навіть не знаючи самого числа ?
Насправді це досить просто. У послідовності є цикл тоді й лише тоді, коли існують два індекси такі, що . Це рівняння можна переписати як , що те саме, що й .
Тому, якщо ми знайдемо два індекси та з , ми знайшли цикл, а також множник числа . Можливо, що . У цьому випадку ми не знайшли власного множника, тож маємо повторити алгоритм з іншим параметром (інше початкове значення , інша константа у поліноміальній функції ).
Щоб знайти цикл, ми можемо використати будь-який поширений алгоритм виявлення циклів.
Алгоритм пошуку циклу Флойда
Цей алгоритм знаходить цикл, використовуючи два вказівники, що рухаються по послідовності з різними швидкостями. Під час кожної ітерації перший вказівник просувається на один елемент уперед, тоді як другий вказівник просувається через кожен другий елемент. Використовуючи цю ідею, легко помітити, що якщо цикл існує, то в певний момент під час проходження циклу другий вказівник наздожене перший. Якщо довжина циклу дорівнює , а — це перший індекс, на якому цикл починається, то алгоритм працюватиме за час .
Цей алгоритм також відомий як алгоритм «черепаха і заєць», за казкою, в якій черепаха (повільний вказівник) і заєць (швидший вказівник) змагаються в забігу.
За допомогою цього алгоритму насправді можна визначити параметри та (також за час і пам'ять ). Коли цикл виявлено, алгоритм поверне 'True'. Якщо послідовність не має циклу, то функція зациклиться нескінченно. Однак, використовуючи ро-алгоритм Полларда, цього можна уникнути.
function floyd(f, x0):
tortoise = x0
hare = f(x0)
while tortoise != hare:
tortoise = f(tortoise)
hare = f(f(hare))
return true
Реалізація
Спершу наведемо реалізацію за допомогою алгоритму пошуку циклу Флойда. Алгоритм загалом працює за час .
- C++
- Python
- TypeScript
- Go
long long mult(long long a, long long b, long long mod) {
return (__int128)a * b % mod;
}
long long f(long long x, long long c, long long mod) {
return (mult(x, x, mod) + c) % mod;
}
long long rho(long long n, long long x0=2, long long c=1) {
long long x = x0;
long long y = x0;
long long g = 1;
while (g == 1) {
x = f(x, c, n);
y = f(y, c, n);
y = f(y, c, n);
g = gcd(abs(x - y), n);
}
return g;
}
from math import gcd
# Python оперує великими числами нативно, тож x*x % n не переповнюється —
# окрема функція mult не потрібна.
def f(x: int, c: int, mod: int) -> int:
return (x * x + c) % mod
def rho(n: int, x0: int = 2, c: int = 1) -> int:
x = x0
y = x0
g = 1
while g == 1:
x = f(x, c, n) # черепаха — один крок
y = f(f(y, c, n), c, n) # заєць — два кроки
g = gcd(abs(x - y), n)
return g
// bigint: x*x для n до 1e18 переповнює number, окрема mult не потрібна
function gcd(a: bigint, b: bigint): bigint {
while (b) [a, b] = [b, a % b];
return a < 0n ? -a : a;
}
function f(x: bigint, c: bigint, mod: bigint): bigint {
return (x * x + c) % mod;
}
function rho(n: bigint, x0 = 2n, c = 1n): bigint {
let x = x0;
let y = x0;
let g = 1n;
while (g === 1n) {
x = f(x, c, n); // черепаха — один крок
y = f(f(y, c, n), c, n); // заєць — два кроки
const d = x - y;
g = gcd(d < 0n ? -d : d, n);
}
return g;
}
import "math/big"
// math/big уникає переповнення при множенні x*x для n до 1e18.
func f(x, c, mod *big.Int) *big.Int {
r := new(big.Int).Mul(x, x)
r.Add(r, c)
return r.Mod(r, mod)
}
func rho(n *big.Int, x0, c int64) *big.Int {
x := big.NewInt(x0)
y := big.NewInt(x0)
cc := big.NewInt(c)
g := big.NewInt(1)
one := big.NewInt(1)
for g.Cmp(one) == 0 {
x = f(x, cc, n) // черепаха — один крок
y = f(f(y, cc, n), cc, n) // заєць — два кроки
diff := new(big.Int).Abs(new(big.Int).Sub(x, y))
g = new(big.Int).GCD(nil, nil, diff, n)
}
return g
}
Наведена нижче таблиця показує значення та під час роботи алгоритму для , та .
Реалізація використовує функцію mult, яка множить два цілих числа без переповнення, застосовуючи тип __int128 з GCC для 128-бітних цілих.
Якщо GCC недоступний, ви можете скористатися ідеєю, подібною до бінарного піднесення до степеня.
- C++
- Python
- TypeScript
- Go
long long mult(long long a, long long b, long long mod) {
long long result = 0;
while (b) {
if (b & 1)
result = (result + a) % mod;
a = (a + a) % mod;
b >>= 1;
}
return result;
}
def mult(a: int, b: int, mod: int) -> int:
# У Python a * b % mod ніколи не переповнюється, тож ця версія потрібна лише
# для ілюстрації ідеї «множення подвоєнням», аналогічної бінарному степеню.
result = 0
a %= mod
while b:
if b & 1:
result = (result + a) % mod
a = (a + a) % mod
b >>= 1
return result
function mult(a: bigint, b: bigint, mod: bigint): bigint {
// У bigint a * b % mod уже коректне; ця версія ілюструє множення подвоєнням.
let result = 0n;
a %= mod;
while (b) {
if (b & 1n) result = (result + a) % mod;
a = (a + a) % mod;
b >>= 1n;
}
return result;
}
// uint64-варіант множення за модулем без переповнення (множення подвоєнням),
// корисний, якщо не хочеться залежати від math/big.
func mult(a, b, mod uint64) uint64 {
var result uint64 = 0
a %= mod
for b > 0 {
if b&1 == 1 {
result = (result + a) % mod
}
a = (a + a) % mod
b >>= 1
}
return result
}
Як альтернатива, ви також можете реалізувати множення Монтгомері.
Як зазначено раніше, якщо складене, а алгоритм повертає як множник, вам доведеться повторити процедуру з іншими параметрами та . Наприклад, вибір не розкладе . Алгоритм поверне . Однак вибір , розкладе його.
Алгоритм Брента
Брент реалізує метод, подібний до методу Флойда, використовуючи два вказівники. Різниця полягає в тому, що замість просування вказівників відповідно на одну й дві позиції, їх просувають на степені двійки. Щойно стане більшим за та , ми знайдемо цикл.
function floyd(f, x0):
tortoise = x0
hare = f(x0)
l = 1
while tortoise != hare:
tortoise = hare
repeat l times:
hare = f(hare)
if tortoise == hare:
return true
l *= 2
return true
Алгоритм Брента також працює за лінійний час, але загалом швидший за алгоритм Флойда, оскільки використовує менше обчислень функції .
Реалізація
Прямолінійну реалізацію алгоритму Брента можна прискорити, опускаючи члени , якщо . Крім того, замість обчислення на кожному кроці, ми перемножуємо члени й фактично перевіряємо лише раз на кілька кроків, відкочуючись назад, якщо перестрибнули.
- C++
- Python
- TypeScript
- Go
long long brent(long long n, long long x0=2, long long c=1) {
long long x = x0;
long long g = 1;
long long q = 1;
long long xs, y;
int m = 128;
int l = 1;
while (g == 1) {
y = x;
for (int i = 1; i < l; i++)
x = f(x, c, n);
int k = 0;
while (k < l && g == 1) {
xs = x;
for (int i = 0; i < m && i < l - k; i++) {
x = f(x, c, n);
q = mult(q, abs(y - x), n);
}
g = gcd(q, n);
k += m;
}
l *= 2;
}
if (g == n) {
do {
xs = f(xs, c, n);
g = gcd(abs(xs - y), n);
} while (g == 1);
}
return g;
}
from math import gcd
def brent(n: int, x0: int = 2, c: int = 1) -> int:
x = x0
g = 1
q = 1
xs = y = 0
m = 128
l = 1
while g == 1:
y = x
for _ in range(1, l):
x = f(x, c, n)
k = 0
while k < l and g == 1:
xs = x
# накопичуємо добуток різниць і рахуємо gcd рідше (раз на m кроків)
for _ in range(min(m, l - k)):
x = f(x, c, n)
q = q * abs(y - x) % n
g = gcd(q, n)
k += m
l *= 2
if g == n: # перестрибнули — відкочуємось по одному кроку
while True:
xs = f(xs, c, n)
g = gcd(abs(xs - y), n)
if g != 1:
break
return g
function brent(n: bigint, x0 = 2n, c = 1n): bigint {
let x = x0;
let g = 1n;
let q = 1n;
let xs = 0n;
let y = 0n;
const m = 128;
let l = 1;
while (g === 1n) {
y = x;
for (let i = 1; i < l; i++) x = f(x, c, n);
let k = 0;
while (k < l && g === 1n) {
xs = x;
// накопичуємо добуток різниць і рахуємо gcd рідше (раз на m кроків)
for (let i = 0; i < m && i < l - k; i++) {
x = f(x, c, n);
const d = y - x;
q = (q * (d < 0n ? -d : d)) % n;
}
g = gcd(q, n);
k += m;
}
l *= 2;
}
if (g === n) { // перестрибнули — відкочуємось по одному кроку
do {
xs = f(xs, c, n);
const d = xs - y;
g = gcd(d < 0n ? -d : d, n);
} while (g === 1n);
}
return g;
}
import "math/big"
func brent(n *big.Int, x0, c int64) *big.Int {
x := big.NewInt(x0)
cc := big.NewInt(c)
g := big.NewInt(1)
q := big.NewInt(1)
one := big.NewInt(1)
xs := big.NewInt(0)
y := big.NewInt(0)
m := 128
l := 1
for g.Cmp(one) == 0 {
y = new(big.Int).Set(x)
for i := 1; i < l; i++ {
x = f(x, cc, n)
}
k := 0
for k < l && g.Cmp(one) == 0 {
xs = new(big.Int).Set(x)
// накопичуємо добуток різниць і рахуємо gcd рідше (раз на m кроків)
for i := 0; i < m && i < l-k; i++ {
x = f(x, cc, n)
diff := new(big.Int).Abs(new(big.Int).Sub(y, x))
q.Mul(q, diff)
q.Mod(q, n)
}
g = new(big.Int).GCD(nil, nil, q, n)
k += m
}
l *= 2
}
if g.Cmp(n) == 0 { // перестрибнули — відкочуємось по одному кроку
for {
xs = f(xs, cc, n)
diff := new(big.Int).Abs(new(big.Int).Sub(xs, y))
g = new(big.Int).GCD(nil, nil, diff, n)
if g.Cmp(one) != 0 {
break
}
}
}
return g
}
Поєднання пробного ділення для малих простих чисел разом із версією Брента ро-алгоритму Полларда дає дуже потужний алгоритм факторизації.